Overthinking CSV With Cesil: Performance
Posted: 2020/11/20 Filed under: code | Tags: cesil Comments Off on Overthinking CSV With Cesil: PerformanceIt’s time to talk about Cesil’s performance.
Now, as I laid out in an earlier post, Cesil’s raison d’etre is to be a “modern” take on a .NET CSV library – not to be the fastest library possible. That said, an awful lot of .NET and C#’s recent additions have had an explicit performance focus. Just off the top of my head, the following additions have all been made to improve performance:
- RyuJit
- Span<T> (and friends)
- Pipelines
- ref structs
- safe stackalloc
- ValueTask
- unmanaged constraint
- ValueTuple
- Intrinsics
- An awful lot of .NET Core
Accordingly, I’d certainly expect a “modern” .NET CSV library to be quite fast.
However, I deliberately chose to wait until now to talk about Cesil’s performance. Since I was actively soliciting feedback on capabilities and interface with Cesil’s Open Questions, it was a real possibility that Cesil’s performance would change in response to feedback. Accordingly, it felt dishonest to lead with performance numbers that I knew could be rapidly outdated.
The Cesil solution has a benchmarking project, using the excellent BenchmarkDotNet library, which includes benchmarks for:
- Reading and Writing static types
- These include comparisons to other CSV libraries
- Reading and Writing dynamic types
- These are compared to their static equivalents
- Various internals
- These are compared to naïve alternative implementations
The command line interface allows selecting single or collections of benchmarks, and running them over ranges of commits – which enables easy comparisons of Cesil’s performance as changes are made.
Benchmarking in general is fraught with issues, so it is important to be clear on what exactly is being compared. The main comparison benchmarks for Cesil compare reading and writing two types of rows (“narrow” and “wide” ones), and a small (10) and large (10,000) number of rows. Narrow rows have a single column of a built-in type, while wide rows have a column for each built-in type. Built-in types benchmarked are:
- byte
- char
- DateTime
- DateTimeOffset
- decimal
- double
- float
- Guid
- int
- long
- sbyte
- short
- string
- uint
- ulong
- ushort
- Uri
- An enum
- A [Flags] enum
- And nullable equivalents of all above ValueTypes
Note that while Cesil supports Index and Range out of the box, most other libraries do not do so at time of writing so they are not included in benchmarks.
The only other library compared to currently is CsvHelper (version 15.0.6 specifically). This is because that is the most popular, flexible, and feature-ful .NET CSV library that I’ve previously used – not because it is particularly slow. It was also created almost a decade ago, so provides a good comparison for “modern” C# approaches.
Benchmarks were run under .NET Core 3.1.9, in X64 process, on a machine running Windows 10 (release 10.0.19041.630) with an Intel Core i7-6900K CPU (3.20GHz [Skylake], having 16 logical and 8 physical cores), and 128 GB of RAM.
Cesil’s benchmarks report both runtime and allocations, meaning that there is quite a lot of data to compare. A full summary is checked in, but I have selected some subsets to graph here.
|
|
|
|
|
|
|
|
|
|
|
|
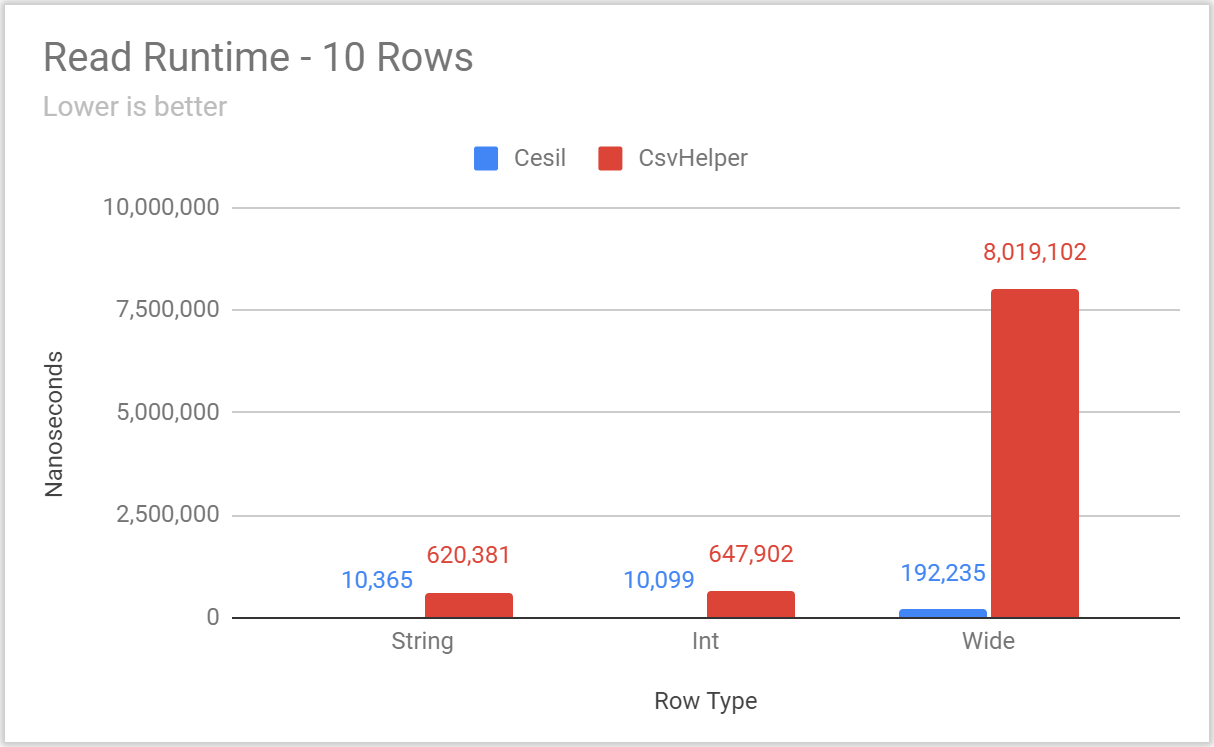

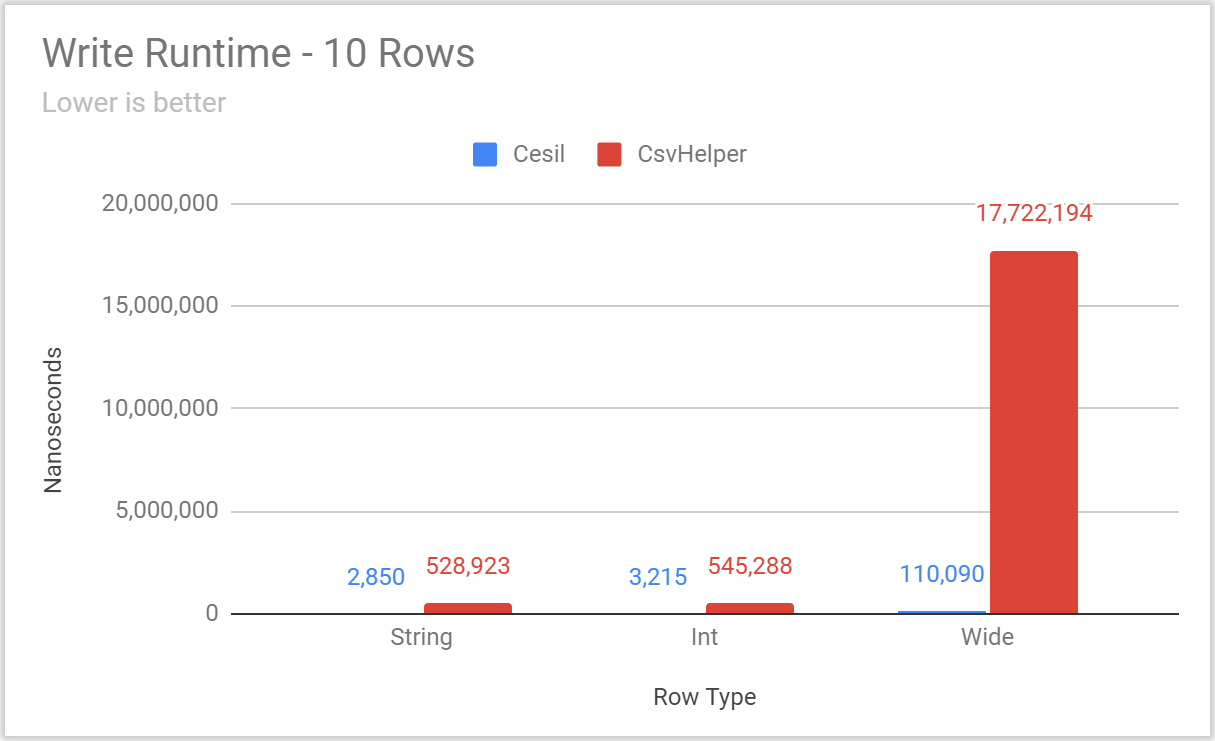
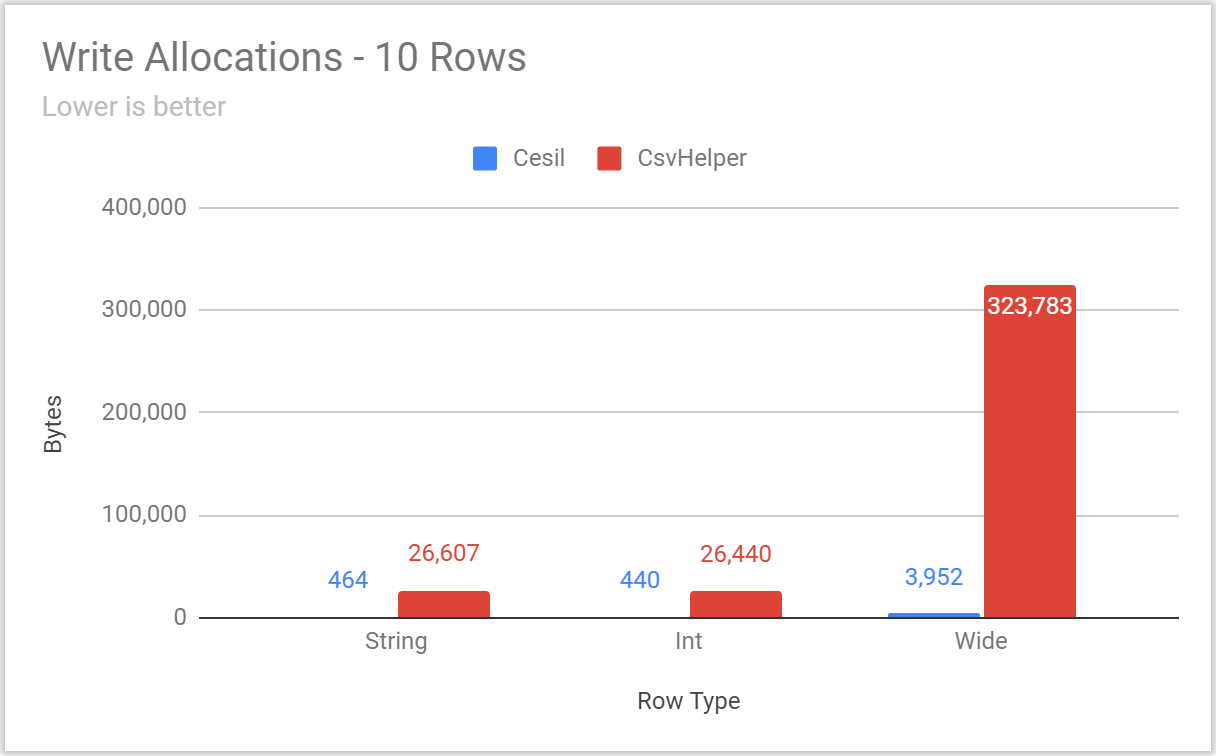

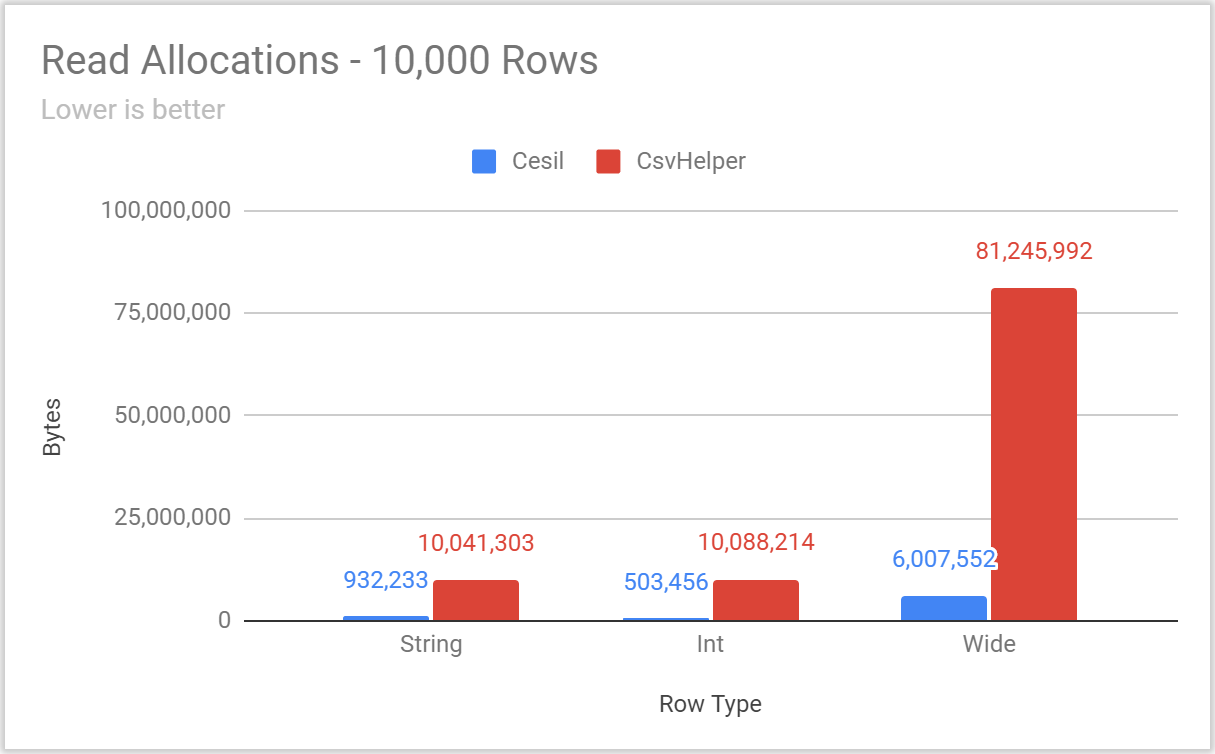


(charts and raw numbers can be found in this Google Sheet)
There are also benchmarks for reading and writing one million of these “wide” rows. Cesil can read ~59,000 wide rows per second (versus ~47,000 for CsvHelper), and write ~97,000 rows per second (versus ~78,000 for CsvHelper).
With all the typical benchmarking caveats (test your own use case, these are defaults not tailor tuned to any particular case, data is synthetic, etc.), Cesil is noticeably faster and performs fewer allocations, especially in the cases where relatively few rows are being written. Be aware that both Cesil and CsvHelper perform a fair amount of setup on the “first hit” for a particular type and configuration pair – and BenchmarkDotNet performs a warmup step that will elide that work from most benchmarks. Accordingly, if your workload is dominated by writing unique types (or configurations) a single time these benchmarks will not be indicative of either library’s performance.
And that wraps up Cesil’s performance, at least for now. There are no new Open Questions for this post, but the issue for naming suggestions is still open.
In the next post, I’ll be digging into Source Generators.

