Your Future On Stack Overflow
Posted: 2013/05/22 Filed under: pontification 18 CommentsI recently spent a while working on a pretty fun problem over at Stack Exchange: predicting what tags you’re going to be active answering in.
Confirmed some suspicions, learned some lessons, got about a 10% improvement on answer posting from the homepage (which I’m choosing to interpret as better surfacing of unanswered questions).
Good times.
Why do we care?
Stack Overflow has had the curious problem of being way too popular for a while now. So many new questions are asked, new answers posted, and old posts updated that the old “what’s active” homepage would cover maybe the last 10 minutes. We addressed this years ago by replacing the homepage with the interesting tab, which gives everyone a customized view of stuff to answer.
The interesting algorithm (while kind of magic) has worked pretty well, but the bit where we take your top tags has always seemed a bit sub-par. Intuitively we know that not all tags are equal in volume or scoring potential, and we also know that activity in one tag isn’t really indicative just in that tag.
What we’d really like in there is your future, what you’re going to want to answer rather than what you already have. They’re related, certainly, but not identical.
Stated more formally: what we wanted was an algorithm that when given a user and their activity on Stack Overflow to date, predicted for each tag what percentage of their future answers would be on questions in that tag. “Percentage” is a tad mislead since each question on Stack Overflow can have up to five tags, so the percentages don’t sum to anything meaningful.
The immediate use of such an algorithm would be improving the homepage, making the questions shown to you more tailored to your interests and expertise. With any luck the insights in such an algorithm would let us do similar tailoring elsewhere.
To TL;DR, you can check out what my system thinks it knows about you by going to /users/tag-future/current on any of the older Stack Exchange sites. The rest of this post is about how I built it, and what I learned doing it.

Unsurprisingly, that’s a pretty good model of how I think about my Stack Overflow participation.
What Do We Know?
A big part of any modeling process is going to be choosing what data to look at. Cast too wide a net and your iteration time explodes, too narrow and you risk missing some easy gains. Practicality is also a factor, as data you technically have but never intended to query en masse may lead you to build something you can’t deploy.
What I ended up using is simply the answers on a site (their text, creation dates, and so on), along with the tags the associated questions had when the answer was posted. This data set has the advantage of being eminently available, after all Stack Exchange has literally been built for the purpose of serving answers, and public knowledge.
At various times I did try using data from the questions themselves and an answerers history of asking, but to no avail. I’m sure there’s more data we could pull in, and probably will over time; though I intend to focus on our public data. In part this is because it’s easier to explain and consume the public data but also because intuitively answerers are making decisions based on what they can see, so it makes sense to focus there first.

Except with about 315,000 different parts.
A Model Of A Stack Exchange
The actual process of deriving a model was throwing a lot of assumptions about how Stack Overflow (and other Stack Exchanges) work against the wall, and seeing what actually matched reality. Painstaking, time consuming, iteration. The resulting model does work (confirmed by split testing against the then current homepage), and backs up with data a lot of things we only knew intuitively.
Some Tags Don’t Matter
It stands to reason that a tag that only occurs once on Stack Overflow is meaningless, and twice is probably just as meaningless. Which begs the question, when, exactly does a tag start to matter? Turns out, before about forty uses a tag on Stack Overflow has no predictive ability; so all these tags aren’t really worth looking at in isolation.
Similarly a single answer isn’t likely to tell us much about a user, what I’d expect is a habit of answering within a tag to be significant. How many answers before it matters? Looks like about three. My two answers in “windows-desktop-gadgets” say about as much about me as my astrological sign (Pisces if you’re curious).

Pictured: the state of programming Q&A before Stack Overflow.
Most People Are Average (That’s Why It’s An Average)
What’s being asked on Stack Overflow is a pretty good indicator of what’s being used in the greater programming world, so it stands to reason that a lot of people’s future answering behavior is going to look like the “average user’s” answering behavior. In fact, I found that the best naive algorithm for predicting a user’s future was taking the site average and then overlaying their personal activity.
Surprisingly, despite the seemingly breakneck speed of change in software, looking at recent history when calculating the site average is a much worse predictor than considering all-time. Likewise when looking at user history, even for very highly active users, recent activity is a worse predictor than all time.
One interpretation of those results, which I have no additional evidence for, is that you don’t really get worse at things over time you mostly just learn new things. That would gel with recent observations about older developers being more skilled than younger ones.
You Transition Into A Tag
As I mentioned above, our best baseline algorithm was predicting the average tags of the site and then plugging in a user’s actual observed history. An obvious problem with that is that posting a single answer in say “java.util.date” could get us predicting 10% of your future answers will be in “java.util.date” even though you’ll probably never want to touch that again.
So again I expected there to be some number of uses of a tag after which your history in it is a better predictor than “site average”. On Stack Overflow, it takes about nine answers before you’re properly “in” the tag. Of course there needs to be a transition between “site average” and “your average” between three and nine answers, and I found a linear one works pretty well.
We All Kind Of Look The Same
Intuitively we know there are certain “classes” of users on Stack Overflow, but exactly what those classes are is debatable. Tech stack, FOSS vs MS vs Apple vs Google? Skill level, Junior vs Senior? Hobbyist vs Professional? Front-end vs Back-end vs DB? And on and on.
Instead of trying to guess those lines in the sand, I went with a different intuition which was “users who start off similarly will end up similarly”. So I clustered users based on some N initial answers, then use what I knew about existing users to make predictions for new users who fall into the cluster.
Turns out you can cut Stack Overflow users into about 440 groups based on about 60 initial tags (or about 30 answers equivalently) using some really naive assumptions about minimum distances in euclidean space. Eyeballing the clusters, it’s (very approximately) Tech stack + front/back-end that divides users most cleanly.

We’d also expect chocolate in there.
One Tag Implies Another
Spend anytime answering on Stack Overflow and you’ll notice certain tags tend to go together. Web techs are really good for this like “html” and “css” and “javascript” and “jquery”, but you see it in things like “ios” and “objective-c”. It stands to reason that answering a few “c#” questions should raise our confidence that you’re going to answer some “linq-to-object” questions then.
Testing that assumption I find that it does, in fact, match reality. The best approach I found was predicting activity in a tag given activity in commonly co-occurring tags (via a variation on principal component analysis) and making small up or down tweaks to the baseline prediction accordingly. This approach depends on there being enough data for co-occurrence to be meaningful, which I found to be true for about 12,000 tags on Stack Overflow.
Trust Your Instincts
Using the Force is optional.
One pretty painful lesson I learned doing all this is: don’t put your faith in standard machine learning. It’s very easy to get the impression online (or in survey courses) that rubbing a neural net or a decision forest against your data is guaranteed to produce improvements. Perhaps this is true if you’ve done nothing “by hand” to attack the problem or if your problem is perfectly suited to off the shelf algorithms, but what I found over and over again is that the truthiness of my gut (and that of my co-workers) beats the one-size-fits-all solutions. You know rather a lot about your domain, it makes sense to exploit that expertise.
However you also have to realize your instincts aren’t perfect, and be willing to have the data invalidate your gut. As an example, I spent about a week trying to find a way to roll title words into the predictor to no avail. TF-IDF, naive co-occurrence, some neural network approaches, and even our home grown tag suggester never quite did well enough; titles were just too noisy with the tools at my disposal.
Get to testing live as fast as you possibly can, you can’t have any real confidence in your model until it’s actually running against live data. By necessity much evaluation has to be done offline, especially if you’ve got a whole bunch of gut checks to make, but once you think you’ve got a winner start testing. The biggest gotcha revealed when my predictor went live is that the way I selected training data made for a really bad predictor for low activity users, effectively shifting everything to the right. I solved this by training two separate predictors (one for low activity, and one for high).
Finally, as always solving the hard part is 90% of the work, solving the easy part is also 90% of the work. If you’re coming at a problem indirectly like we were, looking to increase answer rates by improving tag predictions, don’t have a ton of faith in your assumptions about the ease of integration. It turned out that simply replacing observed history with a better prediction in our homepage algorithm broke some of the magic, and it took about twenty attempts to realize gains in spite of the predictor doing what we’d intended. The winning approach was considering how unusual a user is when compared to their peers, rather than considering them in isolation.
Again, want to see what we think you’ll be active in? Hit /users/tag-future/current on your Stack Exchange of choice.
Making Magic: How Sigil Works
Posted: 2013/05/16 Filed under: code | Tags: sigil 3 Comments
Version 3.0.0 of Sigil was just released (grab it on Nuget and check out the source on Github). The big new feature this release is a disassembler, one which allows for some inspection of the flow of values through a .NET delegate.
But that’s not what I’m writing about. I figure now’s as good a time as any to write up the “how” of Sigil, given that I covered the “what” and “why” in an earlier post and that recent releases have refactored Sigil’s internals into a state I’m happier with.
Bytecode Verifiers And You
In essence Sigil is a “bytecode verifier”. If you’ve done JVM or .NET development you should be familiar with the concept, the bytecode verifiers on those platforms make sure that the class files or assemblies you load contain bytecode that can safely be executed.
The definition of “safe” is very particular, a bytecode verifier doesn’t prevent errors from occurring at execution time but rather prevents invariants of the runtime from being violated. For example, a bytecode verifier would guarantee that invoking an instance method is passed the proper number and types of parameters and that it is invoked against an instance of the appropriate type.
One way to think about bytecode verifiers is that they guarantee that every operation receives the correct types as inputs and every operation leaves the runtime in a well formed state.
Sigil’s Special Features
Where Sigil differs from other bytecode verifiers is that it doesn’t operate on “finished” instruction sequences. It verifies as you build a sequence, failing as soon as it can be sure the sequence is invalid.
Because Sigil deals with incomplete instruction sequences it also has to do with a lot of unknowns, especially around branches. It’s quite common to branch to an instruction you haven’t actually emitted yet or emit instructions that aren’t yet provably reachable, both cases a traditional verifier can never encounter.
Sigil also has to explain itself when it fails, so it has to be able to deliver where and why a given sequence became invalid (which can be far removed from the last emitted instruction because of branches). Similar complications exist when verification is successful, as things like eliding trivial casts and replacing branches with their short forms (which are deferred until an instruction stream is finalized) requires a lot of information about the instruction stream be retained.
Simple Verifying
If you ignore branches, verifying a bytecode sequence is pretty simple. You can think of it as executing instructions as if they consumed and produced types instead of values. Since Sigil is a .NET library I’ll be using .NET examples, though the basic idea applies to all similar verifiers.
For example, assume the following is an implementation of a Func<int>:
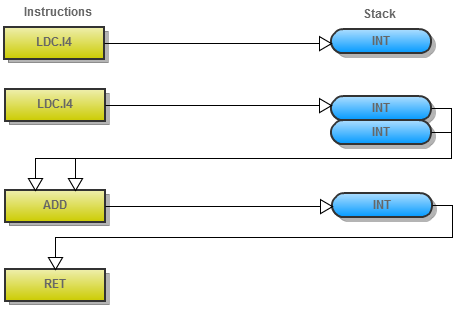
ldc.i4 1 ldc.i4 2 add ret
We know “ldc.i4” consumes nothing, and produces an int, “add” actually consumes and produces a wide range of types but one of them is “int int -> int”. The “ret” instruction either consumes nothing or a single type, dependent on the signature of the method it is used in; in this case it consume an “int” which we know because the method is a “Func<int>”.
I’ve written out the state of the stack (the .NET runtime is specified as a stack machine) after each instruction executes:
// --empty--
ldc.i4 1 // int
ldc.i4 2 // int int
add // int
ret // --empty--
We need to add one more rule, which is that control flow ends with a “ret” which leaves the stack empty, and with that it’s clear that this sequence would verify.
The following sequence wouldn’t verify:
ldc.i4 1 // int ldstr "hello world" // string int mult // !ERROR! ret
Since “mult” doesn’t have a transition from “string int” verification could be shown to fail as soon as “mult” is emitted.
The earliest releases of Sigil were simple verifiers as they didn’t try and trace through. Through version 1.2.9 you instead had to assert types when marking labels under certain circumstances.
Complex Verifying
As soon as you add branches life gets considerably more complicated. Now you have to deal with cases where you can’t infer what types are on the stack immediately.
Consider the following:
ldc.i4 1 br end_label middle_label: add ret end_label: ldc.i4 2 br middle_label
In this example the types passed to “add” are unclear when it is emitted, it’s only when “br middle_label” is encountered that it becomes clear that “add” will verify.
Furthermore, whether or not “ret” verifies depends on the method being built. It would verify if we’re building a Func<int> then it verifies. If we’re building a Func<string> it should fail when emitted, since there’s no way for “add” to pass a string to “ret”. If we’re building a Func<double>, then it should fail when “br middle_label” is emitted since then “add” is known to produce and pass an Int32 to “ret”.
How Sigil Copes
Sigil deals with the complexities of verifying partial sequences in two ways: tracking the possible types on the stack, and creating a verifier for each possible code path.
Reconsidering the above example:
// ** Initial Verifier: V1, with empty stack **
ldc.i4 1 // int
br end_label // int
// ** New Verifier: V2 with unknown stack, V1 stashed **
middle_label:
add // int|long|float|double|etc.
ret // --empty--
// ** New Verifier: V3 with unknown stack, V2 stashed **
end_label: // ** V1 restored (stack is: int) **
ldc.i4 2 // int int
br middle_label // int int (V2 now verified with int int as initial stack)
There’s rather a lot going on now, what with verifiers being stashed and restored. Also note that when “add” is first encountered it places an “or” clause onto the stack, which allows “ret” to verify if it expects any type in that “or” clause.

The logic around creating and restoring verifiers is tricky, but boiled down:
- At an unconditional branch, store the current stack state and remove the current verifiers
- If the branched to label has already been marked, take the current stack and check it against the expected initial stack at that label
- At a conditional branch do the same checks and stores as an unconditional one, but don’t remove the current verifiers
- When marking a label, if there is no verifier create a new one with an unknown initial stack
- If there are stacks stored against that label from previous branches, check that those stacks are consistent and make them the new verifiers initial stack
- Treat “ret” as an unconditional branch which doesn’t store the stack state
- If at any point an instruction is emitted and there is no current verifier, the newly emitted code is unreachable
This logic is captured in Sigil’s RollingVerifier UnconditionalBranch, ConditionalBranch, Return, and Mark methods.
As for tracking all possible values on the stack (as in the “or” with “add” in the previous example), Sigil considers transitions rather than types on the stack. So long as there’s at least one transition that could be taken for every instruction a verifier has seen, the instruction stream is considered verifiable.
Take for example the, rather complex, transitions for “add”:
new[]
{
new StackTransition(new [] { typeof(int), typeof(int) }, new [] { typeof(int) }),
new StackTransition(new [] { typeof(int), typeof(NativeIntType) }, new [] { typeof(NativeIntType) }),
new StackTransition(new [] { typeof(long), typeof(long) }, new [] { typeof(long) }),
new StackTransition(new [] { typeof(NativeIntType), typeof(int) }, new [] { typeof(NativeIntType) }),
new StackTransition(new [] { typeof(NativeIntType), typeof(NativeIntType) }, new [] { typeof(NativeIntType) }),
new StackTransition(new [] { typeof(float), typeof(float) }, new [] { typeof(float) }),
new StackTransition(new [] { typeof(double), typeof(double) }, new [] { typeof(double) }),
new StackTransition(new [] { typeof(AnyPointerType), typeof(int) }, new [] { typeof(SamePointerType) }),
new StackTransition(new [] { typeof(AnyPointerType), typeof(NativeIntType) }, new [] { typeof(SamePointerType) }),
new StackTransition(new [] { typeof(AnyByRefType), typeof(int) }, new [] { typeof(SameByRefType) }),
new StackTransition(new [] { typeof(AnyByRefType), typeof(NativeIntType) }, new [] { typeof(SameByRefType) })
};
One more thing to track when dealing with verifiers is whether or not we know their initial stack, what I call “baseless” in the code. It is not an error for an instruction stream to underflow a baseless verifier, since it’s stack could be anything. Instead of failing verification, Sigil considers the result of underflowing a baseless stack to be a “wildcard” type which satisfies any transition; this is how “add” can pop a value to continue verification after “middle_label”.
Trickier Things
.NET has a couple hairy CIL opcodes that require special handling: dup, localloc, and leave.
“dup” duplicates the current value on the stack, the difficulty being that we only know the type on the stack if we can verify the preceding instructions which isn’t always. Sigil handles this by making “dup” place a special type on the stack, which when encountered by the verifier pushes a copy the preceeding transition’s result or a wildcard if underflowing a baseless verifier.
“localloc” is analogous to alloca(), pushing a pointer to memory on the stack, which requires that only a single value be on the stack when executed. This means the current verifier cannot be baseless to verify. In this case Sigil uses a special transition which asserts that the size of the stack is one if the verifier is based, and is ignored if it is not.
“leave” is an unconditional branch out of an exception or catch block which empties the stack entirely. Sigil considers this equivalent to “pop”-ing exactly the number of items currently on the stack, which like “localloc” means the current verifier cannot be baseless. Like “dup” Sigil uses a special type to indicate that the stack needs to be emptied to the verifier.
Optimizing Emitted Code
There are two kinds of optimizations Sigil can do to emitted CIL: eliding trivial casts, and replacing instructions with their short forms.
Conceptually eliding is straight forward, just keep track of what types are guaranteed to go into a castclass or isinst operation and if those types are assignable to the type encoding with the instruction elide it. Sigil attaches callbacks, like this one, to “castclass” and “isinst” transitions which are called whenever a verifier processes those operations and passed enough information to decide whether to elide themselves or not.
Some short forms are easy, any of the LoadConstant methods with short forms can be changed at call time. The trickier ones are branches, as we need to wait until we’re done emitting code and can calculate offsets. Tracking offsets is handled by BufferedILGenerator (which maintains a cache of byte offsets to each instruction) and a last minute call to Emit.PatchBranches patches all the branch instructions that can fit their offsets into a signed byte.
Optimizing Sigil
Sigil employs some tricks to keep it relatively snappy.
Perhaps most importantly, it doesn’t re-verify operations unless it absolutely has to. Every currently in scope verifier maintains a cache of its state when it last verified the instruction stream and re-uses that cache when new instructions are added. The cache does have to be invalidated when the initial stack state changes, which only happens when branching to or marking labels.
Sigil also tries to keep the number of verifiers in scope limited by discarding any non-baseless verifiers past the first one. Since any verifier that isn’t baseless can be traced back to the start of the method, we know that there are no “or” type clauses on the stack so the verifiers are equivalent going forward even if they took different paths through the code.
Other Tidbits
To wrap this up I’m just going to list some minor things of note found in Sigil.
- Sigil has most of an implementation of Linq-to-Objects to run on pre-.NET 3.5 runtimes, heavily influenced by Jon Skeet’s Edulinq series
- Sigil has it’s own Tuple implementation for similar reasons
- Sigil’s disassembler, while doing a great deal more, started as a replacement for the Mono.Reflection disassembler in our code base
- Sigil’s exception blocks are slightly different from ILGenerators in that you explicitly attach catches and finallys to them, this makes nested exception handling easier to debug
And again, Sigil can be installed from Nuget and the source is available on Github.

