Making Magic: How Sigil Works
Posted: 2013/05/16 Filed under: code | Tags: sigil 3 Comments
Version 3.0.0 of Sigil was just released (grab it on Nuget and check out the source on Github). The big new feature this release is a disassembler, one which allows for some inspection of the flow of values through a .NET delegate.
But that’s not what I’m writing about. I figure now’s as good a time as any to write up the “how” of Sigil, given that I covered the “what” and “why” in an earlier post and that recent releases have refactored Sigil’s internals into a state I’m happier with.
Bytecode Verifiers And You
In essence Sigil is a “bytecode verifier”. If you’ve done JVM or .NET development you should be familiar with the concept, the bytecode verifiers on those platforms make sure that the class files or assemblies you load contain bytecode that can safely be executed.
The definition of “safe” is very particular, a bytecode verifier doesn’t prevent errors from occurring at execution time but rather prevents invariants of the runtime from being violated. For example, a bytecode verifier would guarantee that invoking an instance method is passed the proper number and types of parameters and that it is invoked against an instance of the appropriate type.
One way to think about bytecode verifiers is that they guarantee that every operation receives the correct types as inputs and every operation leaves the runtime in a well formed state.
Sigil’s Special Features
Where Sigil differs from other bytecode verifiers is that it doesn’t operate on “finished” instruction sequences. It verifies as you build a sequence, failing as soon as it can be sure the sequence is invalid.
Because Sigil deals with incomplete instruction sequences it also has to do with a lot of unknowns, especially around branches. It’s quite common to branch to an instruction you haven’t actually emitted yet or emit instructions that aren’t yet provably reachable, both cases a traditional verifier can never encounter.
Sigil also has to explain itself when it fails, so it has to be able to deliver where and why a given sequence became invalid (which can be far removed from the last emitted instruction because of branches). Similar complications exist when verification is successful, as things like eliding trivial casts and replacing branches with their short forms (which are deferred until an instruction stream is finalized) requires a lot of information about the instruction stream be retained.
Simple Verifying
If you ignore branches, verifying a bytecode sequence is pretty simple. You can think of it as executing instructions as if they consumed and produced types instead of values. Since Sigil is a .NET library I’ll be using .NET examples, though the basic idea applies to all similar verifiers.
For example, assume the following is an implementation of a Func<int>:
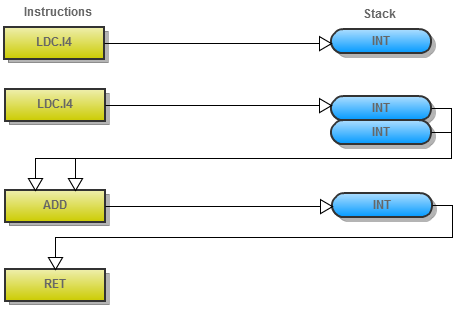
ldc.i4 1 ldc.i4 2 add ret
We know “ldc.i4” consumes nothing, and produces an int, “add” actually consumes and produces a wide range of types but one of them is “int int -> int”. The “ret” instruction either consumes nothing or a single type, dependent on the signature of the method it is used in; in this case it consume an “int” which we know because the method is a “Func<int>”.
I’ve written out the state of the stack (the .NET runtime is specified as a stack machine) after each instruction executes:
// --empty--
ldc.i4 1 // int
ldc.i4 2 // int int
add // int
ret // --empty--
We need to add one more rule, which is that control flow ends with a “ret” which leaves the stack empty, and with that it’s clear that this sequence would verify.
The following sequence wouldn’t verify:
ldc.i4 1 // int ldstr "hello world" // string int mult // !ERROR! ret
Since “mult” doesn’t have a transition from “string int” verification could be shown to fail as soon as “mult” is emitted.
The earliest releases of Sigil were simple verifiers as they didn’t try and trace through. Through version 1.2.9 you instead had to assert types when marking labels under certain circumstances.
Complex Verifying
As soon as you add branches life gets considerably more complicated. Now you have to deal with cases where you can’t infer what types are on the stack immediately.
Consider the following:
ldc.i4 1 br end_label middle_label: add ret end_label: ldc.i4 2 br middle_label
In this example the types passed to “add” are unclear when it is emitted, it’s only when “br middle_label” is encountered that it becomes clear that “add” will verify.
Furthermore, whether or not “ret” verifies depends on the method being built. It would verify if we’re building a Func<int> then it verifies. If we’re building a Func<string> it should fail when emitted, since there’s no way for “add” to pass a string to “ret”. If we’re building a Func<double>, then it should fail when “br middle_label” is emitted since then “add” is known to produce and pass an Int32 to “ret”.
How Sigil Copes
Sigil deals with the complexities of verifying partial sequences in two ways: tracking the possible types on the stack, and creating a verifier for each possible code path.
Reconsidering the above example:
// ** Initial Verifier: V1, with empty stack **
ldc.i4 1 // int
br end_label // int
// ** New Verifier: V2 with unknown stack, V1 stashed **
middle_label:
add // int|long|float|double|etc.
ret // --empty--
// ** New Verifier: V3 with unknown stack, V2 stashed **
end_label: // ** V1 restored (stack is: int) **
ldc.i4 2 // int int
br middle_label // int int (V2 now verified with int int as initial stack)
There’s rather a lot going on now, what with verifiers being stashed and restored. Also note that when “add” is first encountered it places an “or” clause onto the stack, which allows “ret” to verify if it expects any type in that “or” clause.

The logic around creating and restoring verifiers is tricky, but boiled down:
- At an unconditional branch, store the current stack state and remove the current verifiers
- If the branched to label has already been marked, take the current stack and check it against the expected initial stack at that label
- At a conditional branch do the same checks and stores as an unconditional one, but don’t remove the current verifiers
- When marking a label, if there is no verifier create a new one with an unknown initial stack
- If there are stacks stored against that label from previous branches, check that those stacks are consistent and make them the new verifiers initial stack
- Treat “ret” as an unconditional branch which doesn’t store the stack state
- If at any point an instruction is emitted and there is no current verifier, the newly emitted code is unreachable
This logic is captured in Sigil’s RollingVerifier UnconditionalBranch, ConditionalBranch, Return, and Mark methods.
As for tracking all possible values on the stack (as in the “or” with “add” in the previous example), Sigil considers transitions rather than types on the stack. So long as there’s at least one transition that could be taken for every instruction a verifier has seen, the instruction stream is considered verifiable.
Take for example the, rather complex, transitions for “add”:
new[]
{
new StackTransition(new [] { typeof(int), typeof(int) }, new [] { typeof(int) }),
new StackTransition(new [] { typeof(int), typeof(NativeIntType) }, new [] { typeof(NativeIntType) }),
new StackTransition(new [] { typeof(long), typeof(long) }, new [] { typeof(long) }),
new StackTransition(new [] { typeof(NativeIntType), typeof(int) }, new [] { typeof(NativeIntType) }),
new StackTransition(new [] { typeof(NativeIntType), typeof(NativeIntType) }, new [] { typeof(NativeIntType) }),
new StackTransition(new [] { typeof(float), typeof(float) }, new [] { typeof(float) }),
new StackTransition(new [] { typeof(double), typeof(double) }, new [] { typeof(double) }),
new StackTransition(new [] { typeof(AnyPointerType), typeof(int) }, new [] { typeof(SamePointerType) }),
new StackTransition(new [] { typeof(AnyPointerType), typeof(NativeIntType) }, new [] { typeof(SamePointerType) }),
new StackTransition(new [] { typeof(AnyByRefType), typeof(int) }, new [] { typeof(SameByRefType) }),
new StackTransition(new [] { typeof(AnyByRefType), typeof(NativeIntType) }, new [] { typeof(SameByRefType) })
};
One more thing to track when dealing with verifiers is whether or not we know their initial stack, what I call “baseless” in the code. It is not an error for an instruction stream to underflow a baseless verifier, since it’s stack could be anything. Instead of failing verification, Sigil considers the result of underflowing a baseless stack to be a “wildcard” type which satisfies any transition; this is how “add” can pop a value to continue verification after “middle_label”.
Trickier Things
.NET has a couple hairy CIL opcodes that require special handling: dup, localloc, and leave.
“dup” duplicates the current value on the stack, the difficulty being that we only know the type on the stack if we can verify the preceding instructions which isn’t always. Sigil handles this by making “dup” place a special type on the stack, which when encountered by the verifier pushes a copy the preceeding transition’s result or a wildcard if underflowing a baseless verifier.
“localloc” is analogous to alloca(), pushing a pointer to memory on the stack, which requires that only a single value be on the stack when executed. This means the current verifier cannot be baseless to verify. In this case Sigil uses a special transition which asserts that the size of the stack is one if the verifier is based, and is ignored if it is not.
“leave” is an unconditional branch out of an exception or catch block which empties the stack entirely. Sigil considers this equivalent to “pop”-ing exactly the number of items currently on the stack, which like “localloc” means the current verifier cannot be baseless. Like “dup” Sigil uses a special type to indicate that the stack needs to be emptied to the verifier.
Optimizing Emitted Code
There are two kinds of optimizations Sigil can do to emitted CIL: eliding trivial casts, and replacing instructions with their short forms.
Conceptually eliding is straight forward, just keep track of what types are guaranteed to go into a castclass or isinst operation and if those types are assignable to the type encoding with the instruction elide it. Sigil attaches callbacks, like this one, to “castclass” and “isinst” transitions which are called whenever a verifier processes those operations and passed enough information to decide whether to elide themselves or not.
Some short forms are easy, any of the LoadConstant methods with short forms can be changed at call time. The trickier ones are branches, as we need to wait until we’re done emitting code and can calculate offsets. Tracking offsets is handled by BufferedILGenerator (which maintains a cache of byte offsets to each instruction) and a last minute call to Emit.PatchBranches patches all the branch instructions that can fit their offsets into a signed byte.
Optimizing Sigil
Sigil employs some tricks to keep it relatively snappy.
Perhaps most importantly, it doesn’t re-verify operations unless it absolutely has to. Every currently in scope verifier maintains a cache of its state when it last verified the instruction stream and re-uses that cache when new instructions are added. The cache does have to be invalidated when the initial stack state changes, which only happens when branching to or marking labels.
Sigil also tries to keep the number of verifiers in scope limited by discarding any non-baseless verifiers past the first one. Since any verifier that isn’t baseless can be traced back to the start of the method, we know that there are no “or” type clauses on the stack so the verifiers are equivalent going forward even if they took different paths through the code.
Other Tidbits
To wrap this up I’m just going to list some minor things of note found in Sigil.
- Sigil has most of an implementation of Linq-to-Objects to run on pre-.NET 3.5 runtimes, heavily influenced by Jon Skeet’s Edulinq series
- Sigil has it’s own Tuple implementation for similar reasons
- Sigil’s disassembler, while doing a great deal more, started as a replacement for the Mono.Reflection disassembler in our code base
- Sigil’s exception blocks are slightly different from ILGenerators in that you explicitly attach catches and finallys to them, this makes nested exception handling easier to debug
And again, Sigil can be installed from Nuget and the source is available on Github.


I am really impressed Kevin! I really like how Sigil is now. I had to write IL code “by hand” (ILGenerator, but also raw IL though the unmanaged API..not nice) in the past, and getting it correct is not trivial. And spotting where it is wrong it’s even harder..
I especially like how you explained the analysis in presence of branches. I am really curious and have two questions here: does it work with conditional jumps too? What if the two branches (which depend on a condition) produce a different stack, or worse you can predict one of the branches, but the other leads to a more “generic” stack? (does it happen..IDK, honestly?)
Also, you mentioned a disassembler at the beginning: how do you use it? Does it help in the case of, for example, generics? And/or when you are calling/using external functions?
A final question: what would you like to add to Sigil in the future? (something regarding dynamic, perhaps, or more CFG analysis?)
The analysis works with conditional jumps, the only real difference is that when you branch unconditionally you have to “start from scratch” at the next instruction where as conditional branches you don’t since falling through them is legal.
So far as I can tell, it’s not possible for a valid CIL stream to have different expected types at the same instruction. This only applies for complete streams, but Sigil deals with the intermediate cases by keeping an “any of these types”-list around for validation while the stream is completed.
Sigil doesn’t think in generics really, that’s a functionality I’d like to add though. It hasn’t been a focus because they’re both complicated, and only useful in the MethodBuilder use case since with DynamicMethod I think it’s reasonable to assume you know all the types involved already.
Sigil’s disassembler currently only works on Delegates so it’s usage is limited a tad, I’d like to extend it to all methods but I need to add generic support first. It’s seeing some use as a way to determine which properties a delegate might have changed, which is used in tandem with Dapper as a sort of ORM for updates. I’ll probably blog about that use in the future, once we’re sure we’ve got all the kinks worked out.
Sounds great! Especially the extensions to handle generics too. Looks difficult, but exciting 🙂