Another Optimization Exercise – Packing Sparse Headers
Posted: 2022/06/16 Filed under: code Comments Off on Another Optimization Exercise – Packing Sparse HeadersI recently came across an interesting problem at work, and found it was a good excuse to flex some newer .NET performance features (ref locals, spans, and intrinsics). So here’s part 2 of a series that started 6+ years ago.
The Problem
You’ve got a service that accepts HTTP requests, each request encoding many of its details in headers. These headers are well known (that is, there’s a fixed set of them we care about) but the different kinds of requests use different subsets of the headers, out of (say) 192 possible headers each kind of request uses (say) 10 or fewer of the headers. While headers come off the wire as strings, we almost immediately map them to an enumeration (HeaderNames).
Existing code interrogates headers in a few, hard to change, ways which defines the operations that any header storage type must support. Specifically, we must be able to:
- Get and set headers using the HeaderNames enumeration
- Get and set headers directly by name, i.e. someHeaderCollection.MyHeader = “foo” style
- Initialize from a Dictionary<HeaderNames, string>
- Enumerate which HeaderNames are set, i.e. the “Keys” case (akin to Dictionary<T, V>.Keys)
Originally this service used a Dictionary<HeaderNames, string> to store the requests’ headers, but profiling has revealed that reading the dictionary (using TryGetValue or similar) is using a significant amount of CPU.
A new proposal is to instead store the headers in a “Plain Old C# Object” (POCO) with an auto property per HeaderName, knowing the JIT will make this basically equivalent to raw field use (think something like this generated RequestHeaders class in ASP.NET Core). This POCO would have 192 properties making it concerningly large (about 1.5K per instance in a 64-bit process), which has caused some trepidation.
So the question is, can we do better than a Dictionary<HeaderNames, string> in terms of speed and better than the field-rich POCO in terms of allocation. We are going to assume we’re running on modern-ish x86 CPUs, using .NET 6+, and in a 64-bit process.
Other Approaches
Before diving into the “fun” approach, there are two other more traditional designs that are worth discussing.
The first uses a fixed size array as an indirection into a dynamically sized List<string?>. Whenever a header is present we store its value into a List<string?>, and the index of that string into the array at the index equivalent of the corresponding HeaderNames. This approach aims to optimize get and set performance, while deprioritizing the Keys case and only mildly optimizing storage. An implementation of this approach, called the “Arrays” implementation, is included in benchmarking.
The second still uses a Dictionary<HeaderNames, string> to store actual data, but keeps a 192-bit bitfield it uses to track misses. This approach optimizes the get performance when a header is repeatedly read but not present, at the cost of slightly more allocations than the basic Dictionary<HeaderNames, string> implementation. While interesting, the “repeatedly reading missing headers”-assumption wasn’t obviously true at work – so this is not included in benchmarking.
The “Fun” Approach
In essence, the idea is to pack the set headers and their values into an object with a 192-bit bitfield and 10 string fields. The key insight is that a bitfield encodes both whether a header is present and the index of the field it’s stored in. Specifically, the bit corresponding to a header is set when the header is present and the count of less significant bits is the field index its value is stored in.
To illustrate, here’s a small worked example where there are 8 possible headers of which at most 4 may be set.
Imagine we have the following enumeration:
enum HeaderNames { Host = 0, Date = 1, Auth = 2, Method = 3, Encoding = 4, Agent = 5, Cookie = 6, Cached = 7, }
Our state starts like so:

Setting Values
We set Method=”GET”, which corresponds to bit 3. There are no other bits set, so it goes in Value0.
Our state has become:

We then set Date=”Today”, which corresponds to bit 1. There are no less significant bits set, so we also want to store this value in Value0. We need to make sure there’s space, so we slide values 0-2 into values 1-3 before storing “Today” into Value0.

We now set Agent=”IE”, which corresponds to bit 5. There are 2 less significant bits set, so we want to store this into Value2.

Finally we set Auth=”me”, which corresponds to bit 2. There’s 1 less significant bit set, so we want to store this in Value1 after sliding values 1-2 into values 2-3.
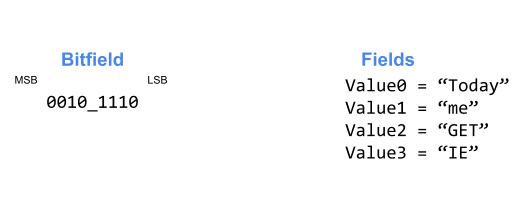
We’re now full, so depending on our needs we can either start rejecting sets or push values that fall out of Value3 into some sort of “overflow” storage.
Getting Values
Looking up values is much simpler than setting them, we just check if the corresponding HeaderNames bit is set and if so count the number of less significant bits also set. That count is the index of the field storing the value for that header.
If we start from the state above:
- For Encoding we see that bit 4 in 0010_1110 is not set, so the Encoding header is not present
- For Method we see that bit 3 in 0010_1110 is set, so the Method header is set. The less significant bits are 0000_0110 which has 2 set bits and thus the value for Method is in Value2 – which is “GET”.
Implementation And Benchmarking
First, let’s implement all 4 approaches: the baseline Dictionary, the proposed Fields, Arrays, and Packed. While some effort has been made to be efficient (using value type enumerators, avoiding some branches, some [MethodImpl] hints, etc.) nothing too crazy has been done to any implementation.
In this blog post I’m only going to pull a few benchmark results out, but the full results are in the git repository. Note that all benchmarks have an iteration count associated with them, so times and allocations are comparable within a benchmark but not across benchmarks. Most benchmarks also explore a number of different parameters (like setting different numbers of headers, or varying the order in which they are set) – in this post I’m only pulling out basic results, but again the full results can be found in the repository.
Set By Enum (Code, Results)
Set benchmarks include allocation tracking, so they are a good place to start.
| Method | OrderAndCount | Mean | Allocated |
| Dictionary | 10, Random | 250.87 μs | 992.19 KB |
| Fields_V1 | 10, Random | 115.97 μs | 1523.44 KB |
| Arrays_V1 | 10, Random | 151.94 μs | 562.5 KB |
| Packed_V1 | 10, Random | 329.09 μs | 117.19 KB |
Importantly, we see that we’ve accomplished our allocation goal – Packed and Arrays use much less memory than the Fields approach (92% and 63% less respectively), and even beat the Dictionary implementation (88% and 43% less respectively).
Unsurprisingly Fields is the fastest (being 64% faster than Dictionary), it’s very difficult to do better than accessing a field. Arrays isn’t that far behind (49% faster), while our first attempt with Packed is substantially slower (30% slower, in fact).
Set Directly By Name (Code, Results)
| Method | OrderAndCount | Mean | Allocated |
| Dictionary | 10, Random | 273.27 μs | 992.19 KB |
| Fields_V1 | 10, Random | 120.12 μs | 1523.44 KB |
| Arrays_V1 | 10, Random | 199.65 μs | 562.5 KB |
| Packed_V1 | 10, Random | 248.31 μs | 117.19 KB |
We do a little better with direct access, because we can hint to the runtime to inline the method behind our property Setters in Packed. This lets the JIT remove a bunch of operations since for any specific property the HeaderNames used is a constant, so a bunch of math gets moved to compile time.
This lets Packed start beating Dictionary by a modest 9%, while still being out speed by Arrays and Fields.
Get By Enum (Code, Results)
For these benchmarks, we read all 192 headers but vary the number of headers that are set.
| Method | NumHeadersSetParam | Mean |
| Dictionary | 10 | 152.79 ms |
| Fields_V1 | 10 | 198.32 ms |
| Arrays_V1 | 10 | 85.20 ms |
| Packed_V1 | 10 | 99.86 ms |
It may seem odd that Fields is the slowest implementation here (being 30% slower than Dictionary), but that’s a consequence of using a switch to find the appropriate field. Even though our values are sequential so a switch becomes a simple jump table, that’s still a good amount of code and branching in each iteration.
Arrays is the fastest (about 44% faster than Dictionary), in part due to a trick where we store a null value in our values List<string?> so we don’t have to have a branch checking for 0s – that’s worth about 8% performance in a microbenchmark comparing the if and branchless version.
Packed doesn’t do badly, out performing Dictionary and Fields (faster by 35% and 50% respectively) and not too much slower than the Arrays approach (about 17%).
Get Directly By Name (Code, Results)
| Method | NumHeadersSetParam | Mean |
| Dictionary | 10 | 179.22 ms |
| Fields_V1 | 10 | 91.73 ms |
| Arrays_V1 | 10 | 95.96 ms |
| Packed_V1 | 10 | 116.51 ms |
Here, as expected, Fields is a clear winner (49% faster than Dictionary). Arrays and Packed, while not as good as Fields, also outperform Dictionary (by 46% and 35% respectively).
Enumerator (Code, Results)
Each type has a custom enumerator (which implements IEnumerator<HeaderNames>, but is used directly) except for Dictionary which uses the built-in KeyCollection.Enumerator. Importantly, these enumerators do not yield values alongside the HeaderNames.
| Method | NumHeadersSetParam | Mean |
| Dictionary | 10 | 91.02 μs |
| Arrays_V1 | 10 | 123.53 μs |
| Fields_V1 | 10 | 2,003.25 μs |
| Packed_V1 | 10 | 297.39 μs |
Finally, a benchmark that Dictionary wins – everything else is much slower, Fields is the worst at 21,000% slower, followed by Packed (220% slower) and Arrays (36% slower). The root reason for this is that, except for Dictionary, none of these implementations are really laid out for enumeration – Arrays has to scan a big (by definition mostly empty) array for non-zero values, Fields has to try reading all possible values (which in V1 involves that big switch mentioned in the Get By Enum benchmarks), and Packed has to do a lot of (in V1, rather expensive) bit manipulation.
Create With Dictionary (Code, Results)
Last but not least, initializing an instance of each type with a Dictionary<HeaderNames, string>. This is a separate benchmark because we can exploit the fact that we’re starting from an empty state to make certain optimizations, like skipping null checks.
| Method | OrderAndCount | Mean | Allocated |
| Dictionary | 10, Random | 96.02 μs | 453.13 KB |
| Fields_V1 | 10, Random | 125.20 μs | 1523.44 KB |
| Arrays_V1 | 10, Random | 164.36 μs | 562.5 KB |
| Packed_V1 | 10, Random | 285.67 μs | 117.19 KB |
Another case where Dictionary is fastest, though by a much smaller margin. Following Dictionary, we have Fields, Arrays, and Packed which are 30%, 71%, and 198% respectively. I’d say this makes sense, Dictionary can simply copy it’s internal state in this case while all other implementations must do more work.
That’s it for the big benchmarks, so where are we starting from?
Overall, the Packed approach is much better in terms of allocations and decent in Get operations, beating Dictionary there but falling short of one or both of the Arrays and Fields approaches. It’s faster than Dictionary when Setting directly by name, but slower when Setting via an enum. And Packed is blown out of the water in Enumeration and Initialization.
If you had to choose right now, you’d probably go with the Arrays approach which has a strong showing throughout. Its only downside is that, while much smaller than the Fields proposal, it is larger than a Dictionary.
But of course, we can do better.
Replacing Switches With Unsafe.Add
Profiling reveals that a lot of time is being spent selecting the appropriate bitfield and values in Packed. This is simple code (just a small switch), so can we do better?
We can, by explicitly laying out the ulongs that hold our bitfield (and strings that hold our values) and turning the switch into a bit of pointer math. This technique is also applicable to the Fields approach, where a great deal of time is spent in simple switches. Using ref locals, ref returns, and Unsafe.Add we don’t need to actually use pointers (nor the unsafe keyword) but we are firmly in “you’d better know what you’re doing”-territory – reading or writing past the end of an instance is going to (eventually) explode spectacularly.
Microbenchmarking shows the “ref local and add”-approach is 4-5x faster than a three-case switch. New versions of Packed and Fields have these optimizations, and they are most impactful in…
Set By Enum (Code, Results)
| Method | OrderAndCount | Mean | Allocated |
| Fields_V1 | 10, Random | 115.97 μs | 1523.44 KB |
| Fields_V2 | 10, Random | 95.25 μs | 1523.44 KB |
| Packed_V1 | 10, Random | 329.09 μs | 117.19 KB |
| Packed_V2 | 10, Random | 320.21 μs | 117.19 KB |
Where Fields V2 is 18% faster than V1, and Packed V2 is 3% faster.
Get By Enum (Code, Results)
| Method | NumHeadersSetParam | Mean |
| Fields_V1 | 10 | 198.32 ms |
| Fields_V2 | 10 | 82.84 ms |
| Packed_V1 | 10 | 99.86 ms |
| Packed_V2 | 10 | 90.40 ms |
Where Fields V2 is 59% faster than V1, and Packed V2 is 9% faster than V1.
Enumerator (Code, Results)
| Method | NumHeadersSetParam | Mean |
| Fields_V1 | 10 | 2,003.25 μs |
| Fields_V2 | 10 | 772.57 μs |
| Packed_V1 | 10 | 297.39 μs |
| Packed_V2 | 10 | 293.06 μs |
Where Fields V2 is 61% faster, and Packed V2 is 1% faster.
Create With Dictionary (Code, Results)
| Method | OrderAndCount | Mean | Allocated |
| Fields_V1 | 10, Random | 125.20 μs | 1523.44 KB |
| Fields_V2 | 10, Random | 115.61 μs | 1523.44 KB |
| Packed_V1 | 10, Random | 285.67 μs | 117.19 KB |
| Packed_V2 | 10, Random | 278.97 μs | 117.19 KB |
Where Fields V2 is 8% faster, and Packed V2 is 3% faster.
Shifting Values With Span<string>
Another round of profiling reveals we should also try to optimize the switch responsible for moving values down to make space for new values in Packed. This is a trickier optimization, because the switch is doing different amounts of work depending on the value.
After some experimentation, I landed on a version that uses Unsafe.Add and Span<string> to copy many fields quickly when we need to move 4+ fields. Modern .NET is quite good at optimizing Span and friends but there is still a small opportunity I couldn’t exploit – we know the memory we’re copying is aligned, but the JIT still emits a (never taken) branch to handle the unaligned case.
This is about 50% faster in ideal circumstances, and matches the switch version in the worst case. Pulling this into our Packed approach (yielding V3) results in more gains compared to V2 in the various Set and Create benchmarks.
This code only runs when we’re setting values, so we see impacts in…
Set By Enum (Code, Results)
| Method | OrderAndCount | Mean | Allocated |
| Packed_V1 | 10, Random | 329.09 μs | 117.19 KB |
| Packed_V2 | 10, Random | 320.21 μs | 117.19 KB |
| Packed_V3 | 10, Random | 175.95 μs | 117.19 KB |
Right away we see great improvement, Packed V3 is 45% faster than V2 when setting values by enum. This means our fancy Packed approach is now faster than using Dictionary (by 30%), though still shy of Arrays and Fields.
Set Directly By Name (Code, Results)
| Method | OrderAndCount | Mean | Allocated |
| Packed_V1 | 10, Random | 248.31 μs | 117.19 KB |
| Packed_V2 | 10, Random | 249.11 μs | 117.19 KB |
| Packed_V3 | 10, Random | 204.55 μs | 117.19 KB |
Our gains are proportionally more modest when going directly by name, as we’re already pretty efficient, but we still see an 18% improvement in Packed V3 compared to V2. We’re now in spitting distance of Arrays (3% slower), though still way short of the Fields approach.
Create With Dictionary (Code, Results)
| Method | OrderAndCount | Mean | Allocated |
| Packed_V1 | 10, Random | 285.67 μs | 117.19 KB |
| Packed_V2 | 10, Random | 278.97 μs | 117.19 KB |
| Packed_V3 | 10, Random | 200.12 μs | 117.19 KB |
Initializing from a dictionary falls between the two, where V3 sees a 29% improvement over V2.
Adding Intrinsics
Next step is to use bit manipulation intrinsics instead of longer form bit manipulation sequences. This is another tool that applies to multiple implementations – for the Arrays approach we can improve the enumerator logic scan for bytes using TZCNT, and with the Packed approach we can directly use POPCOUNT, BZHI, BEXTR, and TZCNT to improve all forms of getting and setting headers.
There’s also one, slightly irritating, trick I’m grouping under “intrinsics”. The JIT knows how to turn (someValue & (1 << someIndex)) != 0 into a BT instruction, while a multi-statement form won’t get the same treatment. This is a really marginal gain (on the order of 2% between versions) but I’d be in favor of BitTest (and BitTestAndSet) intrinsics in a future .NET so I could guarantee this behavior anyway.
Set By Enum (Code, Results)
| Method | OrderAndCount | Mean | Allocated |
| Packed_V1 | 10, Random | 329.09 μs | 117.19 KB |
| Packed_V2 | 10, Random | 320.21 μs | 117.19 KB |
| Packed_V3 | 10, Random | 175.95 μs | 117.19 KB |
| Packed_V4 | 10, Random | 151.33 μs | 117.19 KB |
When setting by enum, V4 is worth another 24% speed improvement over V3. We’ve now more than doubled the performance of our original version.
Set Directly By Name (Code, Results)
| Method | OrderAndCount | Mean | Allocated |
| Packed_V1 | 10, Random | 248.31 μs | 117.19 KB |
| Packed_V2 | 10, Random | 249.11 μs | 117.19 KB |
| Packed_V3 | 10, Random | 204.55 μs | 117.19 KB |
| Packed_V4 | 10, Random | 172.69 μs | 117.19 KB |
As with earlier improvements there’s less proportional win for this operation, but we still see a good 16% improvement in V4 vs V3.
Get By Enum (Code, Results)
| Method | NumHeadersSetParam | Mean |
| Packed_V1 | 10 | 99.86 ms |
| Packed_V2 | 10 | 90.40 ms |
| Packed_V3 | 10 | 80.81 ms |
| Packed_V4 | 10 | 75.98 ms |
Looking up by enumeration sees some small improvement, with V4 improving on V3 by 6%.
Get Directly By Name (Code, Results)
| Method | NumHeadersSetParam | Mean |
| Packed_V1 | 10 | 116.51 ms |
| Packed_V2 | 10 | 116.75 ms |
| Packed_V3 | 10 | 110.72 ms |
| Packed_V4 | 10 | 106.15 ms |
As does getting directly by name, with V4 being about 4% faster than V3.
Enumerator (Code, Results)
| Method | NumHeadersSetParam | Mean |
| Arrays_V1 | 10 | 123.53 μs |
| Arrays_V2 | 10 | 79.92 μs |
| Packed_V1 | 10 | 297.39 μs |
| Packed_V2 | 10 | 293.06 μs |
| Packed_V3 | 10 | 292.59 μs |
| Packed_V4 | 10 | 142.20 μs |
In part because neither approach is particularly well suited to the enumeration case, both Arrays and Packed see big gains from using intrinsics. Arrays V2 is 35% faster than V1, and Packed V4 is 51% faster than V3.
Create With Dictionary (Code, Results)
| Method | OrderAndCount | Mean | Allocated |
| Packed_V1 | 10, Random | 285.67 μs | 117.19 KB |
| Packed_V2 | 10, Random | 278.97 μs | 117.19 KB |
| Packed_V3 | 10, Random | 200.12 μs | 117.19 KB |
| Packed_V4 | 10, Random | 161.73 μs | 117.19 KB |
Finally, we see another 19% improvement in V4 vs V3.
Failed Improvements
There were a couple of things I tried that did not result in improved performance.
Combining Shifting And Field Calculation
Changing TryShiftValueDown to also return the field we need to store the value into. This yielded no improvement, probably because calculating the field is cheap and easily speculated.
Throw Helper
While never hit in any of the benchmarks, all implementations do some correctness checks (for things like maximum set headers, not double setting headers, and null values). A common pattern in .NET is to use a ThrowHelper to reduce code size (and encourage inlining) since calling a static method is usually more compact than creating and raising an exception (on the order of 10 instructions to 1).
This also didn’t yield any improvements, probably because these methods are so small already that adding a dozen or so (never executed) instructions didn’t push the code over any thresholds such that the impact of code size would become measurable.
Branchless Gets
It’s possible, through some type punning and adding an “always null” field to PackedData, to remove this if from Packed’s Get operations.
Basically, you calculate the notSet bool, pun it to a byte, subtract 1, sign extend to an int, and then AND with valueIndex + 1. This will give you a field offset of 0 if the HeaderNames’s bit is not set, and its valueIndex + 1 if it is. In conjunction with an always null field in PackedData at index 0 (causing all the value fields to shift down by one), you’ve now got a branchless Get.
This ends up performing much worse, because although we’re now branchless, we’re now also doing more work (including some relatively expensive intrinsics) on every Get. We’re also making our dependency chain a bit deeper in the “value is set”-case, which can also have a negative impact.
In fairness, this is an optimization that is likely to be heavily impacted by benchmark choices. Since my Get benchmarks tend to have lots of misses, this approach is particularly penalized. It is possible that a scenario where misses were very rare might actually benefit from this approach.
Maintain Separate Counts When Creating With Dictionary
My last failed attempt at an improvement was to try and optimize away the POPCOUNTs needed on adding each new header value when creating a Packed with a Dictionary.
The gist of the attempt was to exploit the fact that we’re always starting from empty in this case, and so we can maintain separate counts in the CreateFromDictionary method for each bitfield we’re modifying. Conceptually we needed three counts: one for the number of bits set before the 0th bitfield (this is always 0), one for the number of bits set before the 1st bitfield (this is the number of times we’ve set a bit in the 0th bitfield), and one for the number of bits set before the 2nd bitfield (this is the number of times we’ve set a bit in the 0th or 1st bitfields).
It’s possible to turn all that count management into a bit of pointer manipulating and an add, plus the reading of a value into more pointer manipulation and type punning. Unfortunately, this ends up being slower (though not by much) than the POPCOUNT approach. I suspect this is due to the deeper dependency chain, or possibly some cache coherence overhead.
Summing Up
After all these optimizations, we’ve managed to push this “Fun” Packed approach quite far. How does it measure up to our original goals, faster than Dictionary<HeaderNames, string>, while smaller than Fields?
We’ve been consistently smaller than a Dictionary and Fields, and managed to sustain that through all our optimizations. So that’s an easy win.
Considering Packed V4’s performance for each operation in turn:
- Set By Enum – 40% faster than Dictionary, but 59% slower than Fields
- Set Directly By Name – 37% faster than Dictionary, but 48% slower than Fields
- Get By Enum – 50% faster than Dictionary, and 8% faster than Fields
- Get Directly By Name – 41% faster than Dictionary, but 16% slower than Fields
- Enumerator – 56% slower than Dictionary, but 82% faster than Fields
- Create With Dictionary – 68% slower than Dictionary, and 40% slower than Fields
It’s a bit of a mixed bag, though there’s only one operation (Initializing From Dictionary) where Packed has worse performance than both Dictionary and Fields. There’s also one operation (Get By Enum) where Packed out performs both.
I’d be comfortable saying Packed is a viable alternative, given the operations it underperforms Dictionary in are the rarer ones and Fields is only actually better at one of those.
It’s worth noting that the Arrays approach is also pretty viable, though its space savings are much more modest (being 380% bigger than Packed, but still 37% the size of Fields in the fully populated cases). Arrays is out performed by Packed in the Set Directly By Name, Get By Enum, and CreateWith Dictionary operations but is better or comparable in the rest.
So yeah, this was a fun exercise that really let me try out some of the newer performance additions to .NET.
Miscellanea
Some clarifications and other things to keep in mind, that didn’t fit neatly anywhere else in this post.
- Benchmarking is always somewhat subjective and while I’ve attempted to mimic the actual use cases we have, it is probably possible to craft similar benchmarks that produce quite different results.
- All benchmarks were run on the same machine (a Surface Laptop 4, plugged in, on a high performance power plan) that was otherwise idle. Relevant specs are included in each benchmark result file.
- Some operations are influenced by the data values, not just the data count. For example, Set operations may spend more time shifting values if the certain HeaderNames are set before others. Where relevant, full benchmarks explore best and worst case orderings. In this post, random order is what was cited as the most “realistic” option but in certain use cases other orderings may be more appropriate.
- This implementation assumes 192 header values, while the motivating case actually has somewhere between 150-160. Since the number of headers in that case is expected to grow over time, and there’s no inherently “correct” choice, I chose to benchmark “the limit” for the Packed approach. This favors Packed somewhat in terms of allocations, and penalizes the V1 of Fields in terms of speed. These biases do not appear to be enough to change any of the conclusions.
- 10 set headers comes from the motivating case, but it also results in Packed being 120 bytes in size (16 bytes for the object header, 8 bytes each for the three bitfields, and 8 bytes each for the ten string references). This fits nicely in one or two cache lines for most CPUs (compared to Fields’ 25 or 13 cache lines), while also leaving space to stash a reference to store “overflow” headers if that’s desired.
- There are non-intrinsic versions of TZCNT and POPCOUNT, which fall back to slower implementations when the processor you’re executing on doesn’t support an intrinsic. I avoided using these because, in this case, the performance is the point – I’d rather raise an exception if the assumption that the operation is fast is false.

