LinqAF: A series of questionable ideas
Posted: 2018/01/16 Filed under: code Comments Off on LinqAF: A series of questionable ideasIntroducing LinqAF, a low allocation re-implementation of LINQ-to-Objects. It’s a pretty questionable idea, but (in my opinion) a really interesting one too.
What is LINQ-to-Objects?
LINQ is a collection of methods provided by .NET that is used to perform a variety of operations like filtering, mapping, grouping, ordering, an so on. There are a multitude of LINQ providers but one of the most commonly used is LINQ-to-Objects which works on plain old .NET objects in memory (others include LINQ-to-Entities, LINQ-to-XML, and the defunct LINQ-to-SQL).
Microsoft’s implementation is done as a series of extension methods to IEnumerable. You can browse the source on Github if you’re curious, but I personally believe the best explanation of this pattern is Jon Skeet’s Edulinq series from 2011.
Low Allocation?

LINQ doesn’t visualize well, so I’m using cat photos to breakup the text.
Many (but not all) of LINQ’s operations can be done without allocating, and when I started LinqAF those were all I intended to provide (LinqAF stood for “Linq: Allocation Free”). When I decided to extend LinqAF to include reversing, sorting, grouping, and the various ToXXX operations (all of which require allocations) I started aiming for “a low number” of allocations.
LinqAF also includes the ability to re-use previously allocated collections, which I’ll expand on in a later post.
Give me the TL;DR
- LinqAF is available on Github and Nuget
- Most operations perform no allocations
- All operations (including foreach statements) work as you’d expect
- It’s “type inference compatible” with System.Linq
- If you’ve written out explicit types, you’ll probably need to make source changes to use LinqAF
- There’s one exception with SelectMany delegates which is covered in a later post
- The whole endeavor qualifies as a Bad Idea™, but a fun one
What’s next?
I cover why it’s possible to replace LINQ so seamlessly, and how it’s possible to do so with no allocations.
An Optimization Exercise
Posted: 2016/04/26 Filed under: code 8 CommentsNick Craver, one of my coworkers at Stack Overflow, tweets out snippets of the Stack Overflow occasionally. About a week ago he showed off a ContainsToken method which has been tuned for performance. This set off a little bit of a benchmarking contest, which I participated in. My final attempt (which is among the fastest) ended up using a lot of tricks, which I think may be of general interest – so I’m going to walk through how the code works.
First, we need to define the problem. We’re creating a function, which:
- Determines if, when split on a given delimiter, a value string contains a given token
- Ordinal comparison of characters is acceptable (this wasn’t clear from the tweet initially)
- Does not allocate
I’m also allowing for optimizations that exploit Stack Overflow’s production environment, so 64-bit Intel and .NET 4.6+ specific tricks are allowed. Since Stack Overflow already has some unsafe code in it, unsafe is also acceptable..
My full solution is available on GitHub, my solution is in Program.cs along with several others. Credit to mattwarren for creating the Benchmark gist.
Here’s my full solution, sans comments, which I’ll be going over line-by-line.
public static bool ContainsTokenMonty(string value, string token, char delimiter = ';')
{
const int charsPerLong = sizeof(long) / sizeof(char);
const int charsPerInt = sizeof(int) / sizeof(char);
const int bytesPerChar = sizeof(char) / sizeof(byte);
if (string.IsNullOrEmpty(token)) return false;
if (string.IsNullOrEmpty(value)) return false;
var delimiterTwice = (delimiter << 16) | delimiter;
var valueLength = value.Length;
var tokenLength = token.Length;
if (tokenLength > valueLength) return false;
int tokenLongs;
bool tokenTrailingInt, tokenTrailingChar;
{
var remainingChars = tokenLength;
tokenLongs = remainingChars / charsPerLong;
tokenTrailingInt = (tokenLength & 0x02) != 0;
tokenTrailingChar = (tokenLength & 0x01) != 0;
}
var tokenByteLength = tokenLength * bytesPerChar;
unsafe
{
fixed (char* valuePtr = value, tokenPtr = token)
{
var curValuePtr = valuePtr;
var endValuePtr = valuePtr + valueLength;
while (true)
{
long* tokenLongPtr = (long*)tokenPtr;
{
for (var i = 0; i < tokenLongs; i++)
{
var tokenLong = *tokenLongPtr;
var valueLong = *((long*)curValuePtr);
if (tokenLong == valueLong)
{
tokenLongPtr++;
curValuePtr += charsPerLong;
continue;
}
else
{
goto advanceToNextDelimiter;
}
}
}
int* tokenIntPtr = (int*)tokenLongPtr;
if (tokenTrailingInt)
{
var tokenInt = *tokenIntPtr;
var valueInt = *((int*)curValuePtr);
if (tokenInt == valueInt)
{
tokenIntPtr++;
curValuePtr += charsPerInt;
}
else
{
goto advanceToNextDelimiter;
}
}
char* tokenCharPtr = (char*)tokenIntPtr;
if (tokenTrailingChar)
{
var tokenChar = *tokenCharPtr;
var valueChar = *curValuePtr;
if (tokenChar == valueChar)
{
tokenCharPtr++;
curValuePtr++;
}
else
{
goto advanceToNextDelimiter;
}
}
if (curValuePtr == endValuePtr || *curValuePtr == delimiter)
{
return true;
}
advanceToNextDelimiter:
while (true)
{
var curVal = *((int*)curValuePtr);
var masked = curVal ^ delimiterTwice;
var temp = masked & 0x7FFF7FFF;
temp = temp + 0x7FFF7FFF;
temp = (int)(temp & 0x80008000);
temp = temp | masked;
temp = temp | 0x7FFF7FFF;
temp = ~temp;
var neitherMatch = temp == 0;
if (neitherMatch)
{
curValuePtr += charsPerInt;
if(curValuePtr >= endValuePtr)
{
return false;
}
continue;
}
var top16 = temp & 0xFFFF0000;
if (top16 != 0)
{
curValuePtr += charsPerInt;
break;
}
var bottom16 = temp & 0x0000FFFF;
if (bottom16 != 0)
{
curValuePtr += 1;
}
}
var remainingBytesInValue = ((byte*)endValuePtr) - ((byte*)curValuePtr);
if (remainingBytesInValue < tokenByteLength)
{
return false;
}
}
}
}
}
It’s no accident that this resembles C, performance critical C# often does. Take note that there are no news (or calls out to functions which may allocate), so this code does zero allocations.
The overall algorithm is as follows:
- Scan forward in
tokenandvalueso long as they are equal - If they are not equal, move back to the start of
tokenand advance invalueuntil after the nextdelimiter- If there is no next
delimiter, return false
- If there is no next
- If the end of
tokenis reached…- If the next character in
valueisdelimiter, or the end ofvaluehas been reached, return true - Otherwise, reset to the start of
tokenand advance invalueuntil after the nextdelimiter
- If the next character in
- If the end of
valueis reached, return false
Now for the line-by-line.
const int charsPerLong = sizeof(long) / sizeof(char); const int charsPerInt = sizeof(int) / sizeof(char); const int bytesPerChar = sizeof(char) / sizeof(byte);
Some convenient constants for later. These could be hardcoded since long, int,and char are always 8, 4, and 2 bytes long in C# – but I find this style easier to reason about.
if (string.IsNullOrEmpty(token)) return false; if (string.IsNullOrEmpty(value)) return false;
This code is copied from the initial tweet, no real optimizations are available here. The check is important to maintain compatibility with the original code.
var delimiterTwice = (delimiter << 16) | delimiter; var valueLength = value.Length; var tokenLength = token.Length;
Some values I’ll need later. Doubling the delimiter will be used to test for it in value, and the lengths will be used to for bounds calculations.
if (tokenLength > valueLength) return false;
The rest of the code assumes that token is no larger than the remaining parts of value, so I check it right here to make sure that’s true. If token couldn’t even fit in value, we don’t even bother to look at either string and just return false.
int tokenLongs;
bool tokenTrailingInt, tokenTrailingChar;
{
var remainingChars = tokenLength;
tokenLongs = remainingChars / charsPerLong;
tokenTrailingInt = (tokenLength & 0x02) != 0;
tokenTrailingChar = (tokenLength & 0x01) != 0;
}
I going to compare token to value in 8-byte/4-char/1-long chunks, so I need to know how many longs can fit in token. Because token isn’t always a multiple of 4 in length, I also need to see if there are 0, 1, 2, or 3 characters after the longs. Note that the single division is by a constant power-of-two, so it gets compiled into something much faster than actual division.
var tokenByteLength = tokenLength * bytesPerChar;
One more useful value before we start actually comparing strings. Since there will be some pointer math later, knowing the number of bytes (importantly not the number of characters) in token will come in handy.
unsafe
{
fixed (char* valuePtr = value, tokenPtr = token)
{
var curValuePtr = valuePtr;
var endValuePtr = valuePtr + valueLength;
Now for the first scary bits. The rest of this method is in an unsafe block which means: we can use pointers, and we have to do our own bounds checking with those pointers.
I take and pin pointers to value and token, make a copy of the value pointer (so it can be mutated, which pointers declared in a fixed block cannot be), and calculate endValuePtr so we can use it to do bounds checks on value.
while (true)
{
long* tokenLongPtr = (long*)tokenPtr;
{
for (var i = 0; i < tokenLongs; i++)
{
var tokenLong = *tokenLongPtr;
var valueLong = *((long*)curValuePtr);
if (tokenLong == valueLong)
{
tokenLongPtr++;
curValuePtr += charsPerLong;
continue;
}
else
{
goto advanceToNextDelimiter;
}
}
}
Here I start comparing the token and value strings. Earlier I calculated how many longs fit in value, so it’s a simple for loop to make sure they all match. Each iteration compares 4 characters worth of value to token, if they match I continue the loop if they don’t we goto advanceToNextDelimiter. This is a big win for larger tokens, having a quarter the comparisons and branches.
Important things to note: the long* casts are free, and curValuePtr being incremented is faster than you might assume (since charsPerLong is a const, the increment value is pre-calculated instead of involving a multiplication).
int* tokenIntPtr = (int*)tokenLongPtr;
if (tokenTrailingInt)
{
var tokenInt = *tokenIntPtr;
var valueInt = *((int*)curValuePtr);
if (tokenInt == valueInt)
{
tokenIntPtr++;
curValuePtr += charsPerInt;
}
else
{
goto advanceToNextDelimiter;
}
}
Then essentially the same check, but for a single int now – comparing two characters at a time isn’t as good as four but it’s not nothing. Whether or not this check was necessary was determined earlier, so tokenTrailingInt is unchanging across a single call – this is good for branch prediction.
char* tokenCharPtr = (char*)tokenIntPtr;
if (tokenTrailingChar)
{
var tokenChar = *tokenCharPtr;
var valueChar = *curValuePtr;
if (tokenChar == valueChar)
{
tokenCharPtr++;
curValuePtr++;
}
else
{
goto advanceToNextDelimiter;
}
}
And then again for a single char.
if (curValuePtr == endValuePtr || *curValuePtr == delimiter)
{
return true;
}
If this chunk of code is reached then every character in token has been matched, all that’s left is to make sure that either a delimiter or the end of value has been reached. If it has then we’ve got a match and return true, otherwise we fall through to advanceToNextDelimiter.
advanceToNextDelimiter:
while (true)
{
var curVal = *((int*)curValuePtr);
var masked = curVal ^ delimiterTwice;
var temp = masked & 0x7FFF7FFF;
temp = temp + 0x7FFF7FFF;
temp = (int)(temp & 0x80008000);
temp = temp | masked;
temp = temp | 0x7FFF7FFF;
temp = ~temp;
var neitherMatch = temp == 0;
if (neitherMatch)
{
curValuePtr += charsPerInt;
if(curValuePtr >= endValuePtr)
{
return false;
}
continue;
}
This code advances curValuePtr forward until a delimiter is found. There’s a clever combination of tricks here to allow checking two characters with one branch.
The first trick is advancing two characters at a time (thus the int* cast), and being willing to advance 1 character past the end of value. This works because C# guarantees that a string coerced to a char* is terminated with a null character (not a null byte), so there’s always two additional bytes at the end of the string for us to read into whether we need them or not.
The second trick is a series of bit twiddlings, as follows:
- XOR
delimiterTwiceintocurVal, making the the top or bottom char-sized chunks ofmaskedall 0 if they matchdelimiterdelimiterTwicewas precalculated
- AND
maskedwith0x7FFF7FFF, clearing the high bits in the top and bottom char-sized chunks intemp, store the result intemp - ADD
0x7FFF7FFFtotemp, causing the high bits in the top and bottom char-sized chunks oftempto be 1 if any of the low bits in those respective chunks are set - AND
tempwith0x80008000, clearing all but the high bits in the top and bottom char-sized chunks intemp - OR
tempwithmasked, making sure the high bits in each char-sized chunk are set intempwhen the high-bits inmaskedare. - OR
tempwith0x7FFF7FFF, set all the low bits in the char-sized chunks intempwhich will make temp all 1s if both char-sized chunks incurValdo not match delimiter - INVERT
temp, making it all 0s if step #5 made it all 1s - COMPARE
tempagainst 0, settingneitherMatchif so
This is followed up with an if that’s taken if neitherMatch is set in which I increment the pointer into value by two chars. There’s then a bounds check, comparing curValPtr to endValuePtr (which was pre-calculated for this purpose) and false is returned if the bounds have been exceeded. Note that endValuePtr points at the null-terminator, so bailing when curValPtr is equal to it is correct.
var top16 = temp & 0xFFFF0000;
if (top16 != 0)
{
curValuePtr += charsPerInt;
break;
}
var bottom16 = temp & 0x0000FFFF;
if (bottom16 != 0)
{
curValuePtr += 1;
}
If this code is run a delimiter has been found but curValuePtr isn’t pointing to that character, just to the int that contains it. top16 and bottom16 contain the top and bottom chars from temp, whichever one isn’t all zeros is the one that contained the delimiter. Depending on which is set, curValuePtr is incremented so that it points at the first character after the delimiter.
Note because we’re executing on a little-endian architecture but C# is big-endian the increment sizes here appear to be flipped. Also remember that token cannot be empty, and that is checked at the start of the method, so checking the second char (in top16) first isn’t an error.
var remainingBytesInValue = ((byte*)endValuePtr) - ((byte*)curValuePtr);
if (remainingBytesInValue < tokenByteLength)
{
return false;
}
This code runs once the next delimiter has been found, and curValuePtr advanced to one char past it. It is necessary to reassert that there’s enough space remaining in value for token to fit, just as was asserted back towards the start of the method.
The space check is done in bytes instead of chars (the casts are free) because counting the number of chars between two pointers is a subtraction followed by a division, but counting the number of bytes is only a subtraction. Pre-calculating tokenByteLength was done for this purpose.
Then the while loop begins again, and continues until a match is found or value is exhausted.
Aaaaaaand that’s it. Performance wise, this is about 15x faster than the original ContainsToken code and something like 40% faster than than the next best implementation.
I’m not sure I’d encourage anyone to use this code, as relies on several subtleties which make it hard to understand. It also isn’t tuned for 32-bit architectures, or correct on big-endian ones. Both could be fixed, but require some build tweaks which aren’t particularly interesting or portable themselves.
It sure was fun to write though.
Scripting and Profiling Improvements in StackExchange.Redis
Posted: 2015/07/24 Filed under: code Comments Off on Scripting and Profiling Improvements in StackExchange.RedisAt Stack Exchange, we make pretty heavy use of Redis. We’re so invested we’ve had our best minds build not one, but two different .NET libraries for it. Recent(ish) experience with the Providence project has prompted additions to the modern library, StackExchange.Redis, in the realms of Lua scripting and Profiling.
Lua Scripting Improvements
StackExchange.Redis already had full support for Redis’s scripting commands when Providence started, but Lua scripting wasn’t really used at StackExchange at that time. Early versions of Providence started making extensive use of Lua scripts to make atomic updates to our data during our daily refresh process, and we started having painful experiences. The root cause of our pain was that Redis requires you write your script using KEYS and ARGV arrays to pass parameters.
Here’s a toy example to illustrate the issue. The command
eval "redis.call('set', KEYS[1], ARGV[1])" 1 theKey 1 theArg
rendered in C# as
IDatabase db = /* ... */
var theKey = /* ... */
var theArg = /* ... */
db.ScriptEvaluate(
"redis.call('set', KEYS[1], ARGV[1])",
new RedisKey[] { theKey },
new RedisValue [] { theArg }
);
sets one “the-key” to “the-arg”. The actual script in your source would be “redis.call(‘set’, KEYS[1], ARGV[1])” which is… less than ideal, especially once your scripts start getting complicated.
In recent versions of StackExchange.Redis there’s an alternative, use the new LuaScript class. This lets you refer to variables by name in a manner inspired by Dapper (the Stack Exchange micro-ORM).
The previous example would now be rendered in C# as:
IDatabase db = /* ... */
var theKey = /* ... */
var theArg = /* ... */
var script = LuaScript.Prepare("redis.call('set', @theKey, @theArg)");
db.ScriptEvaluate(script, new { theKey, theArg });
LuaScript rewrites your script to refer to ARGV and also handles mapping your parameters to the appropriate ARGV index (and places any parameters of type RedisKey into the KEYS array as well, so as to play nicely with Redis Cluster). You can use any object to specify parameters, so long as it has a public field or property for each @parameter.
To avoid the overhead of transmitting the script text for every call to IDatabase.ScriptEvaluate, you can convert a LuaScript into a LoadedLuaScript like so:
IServer server = /* ... */ LuaScript script = /* ... */ LoadedLuaScript loaded = server.ScriptLoad(script);
The LoadedLuaScript class provides the same functionality as the LuaScript class, but uses the SCRIPT LOAD and EVALSHA commands to avoid re-transmitting the entire script when evaluated.
Profiling Improvements
While Redis is really (really really) fast, at Stack Overflow we’ve still been profiling its impact on page load times since time immemorial. Everytime a developer looks at Stack Overflow, they get informed of how much time was spent in talking to Redis.

That 48.8ms includes a fair amount of “moderator only” work too.
The way Stack Overflow uses Redis is analogous to how we use SQL Server – send query, wait for it to complete, read the response, then proceed. StackExchange.Redis multiplexes and pipelines so the application doesn’t block waiting for responses, but individual HTTP requests do as a consequence of their logic.
Accordingly, Stack Overflow’s Redis profiling code has been conceptually:
var watch = Stopwatch.StartNew(); IDatabase db = /* ... */ db.GetString(/* ... */); watch.Stop(); PushToProfilingStats(watch.Elapsed);
Obviously the actual code is more sophisticated.
Providence, however, works quite differently. For each request to Providence, it dispatches several Redis commands and then combines them once they all finish.
In other words, the Providence Redis code tends to look like:
IDatabase db = /* ... */
var inFlight =
new List<Task>
{
GatherFooFieldsAsync(), // does an async redis query or two
GatherBarFieldsAsync() // likewise
/* and so on */
};
await Task.WhenAll(inFlight);
To better support profiling in situations like Providence’s, StackExchange.Redis now has the IProfiler interface, the RegisterProfiler method, the BeginProfiling method, and the FinishProfiling method. These new additions are used by StackExchange.Redis to associate dispatched commands with a user provided context object, even when using the async and await keywords.
Exactly how to determine context is application specific but the following code is used in the Providence API project, which is a stock MVC5 website.
// The IProfiler implementation
public class RedisProfiler : IProfiler
{
const string RequestContextKey = "RequestProfilingContext";
public object GetContext()
{
var ctx = HttpContext.Current;
if (ctx == null) return null;
return ctx.Items[RequestContextKey];
}
public object CreateContextForCurrentRequest()
{
var ctx = HttpContext.Current;
if (ctx == null) return null;
object ret;
ctx.Items[RequestContextKey] = ret = new object();
return ret;
}
}
// In Global.asax.cs
static RedisProfiler RedisProfiler;
static ConnectionMultiplexer RedisConnection;
protected void Application_Start()
{
RedisProfiler = new RedisProfiler();
RedisConnection = ConnectionMultiplexer.Connect(...);
RedisConnection.RegisterProfiler(RedisProfiler);
// and actual app startup logic ...
}
protected void Application_BeginRequest()
{
var ctxObj = RedisProfiler.CreateContextForCurrentRequest();
if (ctxObj != null)
{
RedisConnection.BeginProfiling(ctxObj);
}
// and actual per-request logic ...
}
protected void Application_EndRequest()
{
var ctxObj = RedisProfiler.GetContext();
if (ctxObj != null)
{
var timings = RedisConnection.FinishProfiling(ctxObj);
var totalCommands = 0;
double totalMilliseconds = 0;
foreach (var timing in timings)
{
totalCommands++;
totalMilliseconds += timing.ElapsedTime.TotalMilliseconds;
}
// and then perf recording logic ...
}
// and actual end of request logic ...
}
More examples of profiling with different notions of context can be found in the StackExchange.Redis profiling tests.
Profiling provides details on each command dispatched, not just their count and time to execute. Timings are exposed as IProfiledCommands, which includes information about:
- The Redis instance the command was sent to
- The DB the command was run in
- The command itself
- Any CommandFlags specified
- When the command was created, which corresponds to when the StackExchange.Redis method was called
- How long it took to enqueue the command after it was created
- How long it took to send the command after it was enqueued
- How long it took Redis to respond after the command was sent
- How long it took to process the response after it was received
- Total time elapsed from command creation til the response was processed
- If the command was a retransmission due to Redis Cluster
- If the command was a retransmitted, a reference to the original commands timings
- If the command was a retransmission, whether it was an ASK or MOVED that prompted it
StackExchange.Redis is available on GitHub and NuGet
Providence: Matching people to jobs
Posted: 2015/02/04 Filed under: pontification Comments Off on Providence: Matching people to jobsThis post is part of a series on the Providence project at Stack Exchange, the first post can be found here.
We’ve gone over building the “developer-kind” and “technology” classifiers, but we’ve yet to describe actually using these predictions for anything. We started with better targeting for Stack Overflow Careers job listings, this was an attractive place to start because our existing system was very naïve, there was enough volume to run experiments easily, and mistakes wouldn’t be very harmful to our users.
The Challenge

In a nutshell, the challenge was: given a person and a set of job listings, produce a prediction of how well the person “fits” each of the jobs. We wanted to produce a value for each job-person pair, rather than just picking some number of jobs for a person, so we could experiment independently in the final ad selection approaches.
To quickly recap what we had to work with: for each person who visits Stack Overflow, we had 11 developer-kind percentage labels, 15 technology percentage labels, and the tag view data which was used to generate those sets of labels; for each job listed on Stack Overflow Careers, we had a list of preferred developer-kinds, preferred technologies, and some tags related to the job.
When designing this algorithm, there were a few goals we had to keep in mind. Neither overly broad jobs (ie. “Web Developer, Any Platform”) nor overly narrow jobs (ie. “ASP.NET MVC2, EF4, and F# in Brownsville”) should dominate. Similarly, while no single label should overwhelm the others, the algorithm should incorporate knowledge of how significant our experimentation revealed the different labels to be. This algorithm was also one of the few pieces of Providence that needed to run in real time.
The Algorithm
The end result was very simple, and can be broken down into the following steps:
- Mask away any developer-kind and technology labels on the person that are not also in the job
- So a job without “Android Developer” will ignore that label on the person
- Sum each developer-kind percentage label that remains
- Sum each technology percentage label that remains
- Determine the tag the person is most active in which also appears on the job, if any
- Calculate what percentage of a person’s overall tag activity occurred in the tag chosen in the previous step
- Scale the percentages calculated in steps 3, 4, & 5 by some pre-calculated weights (see below) and sum them
- Determine the largest possible value that could have been calculated in step 6
- Divide the value of step 6 by the value in step 7, producing our final result
Conceptually, the above algorithm determines the features of a person who would be perfect for a job, and then determine how closely the actual person we’re considering matches.
The per-feature weights it incorporates let us emphasize that certain features are better predictors of a match than others. The least predictive feature is developer-kind, so it is given a weight of one, while technologies and tag matches have weights of two and three because they are roughly two and three times as predictive, respectively. We determined the weight for each feature with experiments in which each feature was used alone to target ads, then compared the relative improvement observed for each feature. These weights also matched our intuition; it makes sense that being a Full Stack Web Developer instead of a Back End Web Developer doesn’t matter as much as being unfamiliar with the technology stack, which itself isn’t as significant as lacking the domain knowledge implied by a particular tag.
Once we tested this algorithm and determined it worked, we had to decide what to do when it didn’t have enough information to make any intelligent predictions. This can happen in two cases: if we know nothing about the user (if they’re brand new, or have opted-out of Providence), and if we know nothing about the job (it may be a crazy outlier, badly entered, or just plain a bad job). In both cases we decided to predict a low, but non-zero, default value; this means that an “empty” person will still get a reasonable mix of jobs and that an “empty” job will still get some exposure. This default value was selected by randomly sampling people and averaging how well they match all the non-empty jobs we’ve ever seen, then adjusting that average down by one standard deviation. In practice, this means the default ranks somewhere between 30% and 50% of the non-empty matches calculated for most users.
There were a few non-Providence concerns to handle after nailing down this algorithm before we could ship the final product. We needed to constrain ads geographically, chose a subset of ads based on their predicted weights, and serve the actual ads on Stack Overflow. All of these were left to our ad server team, and dealt with without resorting to any machine learning trickery.
That wraps up the particularly data and machine learning-focused bits of Providence, but this isn’t the last post. Jason Punyon will continue the series over on his blog.
Next up: All the testing we did, and what we learned from it
Providence: What technologies do you know?
Posted: 2015/01/29 Filed under: pontification Comments Off on Providence: What technologies do you know?This post is part of a series on the Providence project at Stack Exchange, the first post can be found here.
Having already built a classifier for “developer-kinds”, we next set out to determine what technologies people are using. What we considered to be distinct technologies are things like “Microsoft’s web stack” or “Oracle’s database servers,” which are coarser groupings than say “ASP.NET” or “Oracle 11g.”
It was tempting to consider these technologies to be more specific developer-kinds, but we found that many people are knowledgeable about several technologies even if they specialize in only one or two kinds of development. For example, many developers are at least passingly familiar with PHP web development even if they may be exclusively writing iOS apps for the time being.
The Data
Our starting point for this problem was to determine what technologies are both actually out there and used by large segments of the developer population. We got the list of technologies by looking at the different job openings listed on Stack Overflow Careers for which companies are trying to hire developers. This was a decent enough proxy for our purposes. After excluding a few labels for being too ambiguous, we settled on the following list:
- PHP
- Ruby On Rails
- Microsoft’s Web Stack (ASP.NET, IIS, etc.)
- Node.js
- Python’s Web Stacks (Django, Flask, etc.)
- Java’s Web Stacks (JSP, Struts, etc.)
- WordPress
- Cloud Platforms (Azure, EC2, etc.)
- Salesforce
- SharePoint
- Windows
- OS X
- Oracle RDBMS
- Microsoft SQL Server
- MySQL
Something that stands out in these labels is the prevalence of Microsoft technologies. We suspect this is a consequence of two factors: Microsoft’s reach is very broad due to its historical dominance of the industry, and Stack Overflow itself (and thus the jobs listed on Careers Stack Overflow) has a slight Microsoft bias due to early users being predominantly Coding Horror and Joel On Software readers.
Furthermore, mobile technologies are unrepresented in the list, likely because they are already adequately covered by the developer-kind predictions. The reality on the ground is that developing for a particular mobile platform very strongly implies the use of particular technologies. While some people do use things like Xamarin or Ruby Motion to develop for iOS and Android, the vast majority do not.
The Classifier
We knew that many tags on Stack Overflow correlate strongly with a particular technology, but others, such as [sql], were split between several different technologies. To determine these relationships, we looked at tag co-occurrence on questions. For example, given that [jsp] is a Java Web Stacks tag which co-occurs quite a bit more with [java] than [windows] tells us that viewing a question with the [java] should count more towards the “Java Web Stacks” technologies than the “Windows” technologies. Repeatedly applying this observation allowed us to grow clouds of related tags, each with a weight proportional to their co-occurrence with tags of a known quality. One small tweak over this simple system was to reduce the weights of tags that are commonly found in several technologies, such as [sql] which co-occurs with many different database, application, and web technologies.
This approach required that we hand-select seed tags for each technology. The seeds used in the first version of Providence for each technology are:
- PHP – php, php-*, zend-framework
- Ruby On Rails – ruby-on-rails, ruby-on-rails-*, active-record
- Microsoft’s Web Stack – asp.net, asp.net-*, iis, iis-*
- Node.js – node.js, node.js-*, express, npm, meteor
- Python’s Web Stacks – django, django-*, google-app-engine, flask, flask-*
- Java’s Web Stacks – jsp, jsp-*, jsf, jsf-*, facelets, primefaces, servlets, java-ee, struts*, spring-mvc, tomcat
- WordPress – wordpress, wordpress-*
- Cloud Platforms – cloud, azure, amazon-ec2, amazon-web-services, amazon-s3
- Salesforce – salesforce, salesforce-*
- SharePoint – sharepoint, sharepoint-*, wss, wss-*
- Windows – windows, windows-*, winapi, winforms
- OS X – osx, osx-*, cocoa, applescript
- Oracle RDBMS – oracle, oracle*, plsql
- Microsoft SQL Server – sql-server, sql-server-*, tsql
- MySQL – mysql, phpmyadmin
By this point, the technology classifier was functionally complete, but in order to reduce some noise in our predictions, we decided to constrain the number of tags we consider to 500 per technology and ignore any tags that are used on less than 0.05% of Stack Overflow questions.
Next up: Actually using Providence for something useful
Providence: Machine Learning At Stack Exchange
Posted: 2015/01/27 Filed under: pontification 3 CommentsAt Stack Exchange, we’ve historically been pretty loose with our data analysis. You can see this in the “answered questions” definition (has an accepted answer or an answer with score > 0), “question quality” (measured by ad hoc heuristics based on votes, length, and character classes), “interesting tab” homepage algorithm (backed by a series of experimentally determined weights), and rather naïve question search function.
 This approach has worked for a long time (turns out your brain is a great tool for data analysis), but as our community grows and we tackle more difficult problems we’ve needed to become more sophisticated. For example, we didn’t have to worry about matching users to questions when we only had 30 questions a day but 3,500 a day is a completely different story. Some of our efforts to address these problems have already shipped, such as a more sophisticated homepage algorithm, while others are still ongoing, such as improvements to our search and quality scoring.
This approach has worked for a long time (turns out your brain is a great tool for data analysis), but as our community grows and we tackle more difficult problems we’ve needed to become more sophisticated. For example, we didn’t have to worry about matching users to questions when we only had 30 questions a day but 3,500 a day is a completely different story. Some of our efforts to address these problems have already shipped, such as a more sophisticated homepage algorithm, while others are still ongoing, such as improvements to our search and quality scoring.
One of our other efforts is to better understand our users, which led to the Providence project. Providence analyzes our traffic logs to predict some simple labels (like “is a web developer” or “uses the Java technology stack”) for each person who visits our site. In its early incarnation, we only have a few labels but we’re planning to continue adding new labels in order to build new features and improve old ones.
While we can’t release the Stack Overflow traffic logs for privacy reasons, we believe it’s in the best interest of the community for us to document the ways we’re using it. Accordingly, this is the first post in a series on the Providence project. We’re going to cover each of the individual predictions made, as well as architecture, testing, and all the little (and not-so-little) problems we had shipping version 1.0.
We have also added a way for any user to download their current Providence prediction data because it’s theirs and they should be able to see and use it as they like. Users can also prevent other systems (Careers, the Stack Overflow homepage, etc.) from querying their Providence data if they want to.
First up: What kind of developer are you?
One of the first questions we wanted Providence to answer was ‘What “kind” of developer are you?’. This larger question also encompassed sub-questions:
- What are the different “developer-kinds”?
- How much, if at all, do people specialize in a single “kind” of development?
- Among these different kinds of developers, do they use Stack Overflow differently?
We answered the first sub-question by looking at a lots and lots of résumés and job postings. While there is definitely a fair amount of fuzziness in job titles, there’s a loose consensus on the sorts of developers out there. After filtering out some labels for which we just didn’t have much data (more on that later), we came up with this list of developer-kinds:
- Full Stack Web Developers
- Front End Web Developers
- Back End Web Developers
- Android Developers
- iOS Developers
- Windows Phone Developers
- Database Administrators
- System Administrators
- Desktop Developers
- Math/Statistics Focused Developers
- Graphics Developers
The second sub-question we answered by looking at typical users of Stack Overflow. Our conclusion was that although many jobs are fairly specialized, few developers focus on a single role to the exclusion of all else. This matched our intuition, because it’s pretty hard to avoid exposure to at least some web technologies, not to mention developers love to tinker with new things for the heck of it.
Answering the final sub-question was nothing short of a leap of faith. We assumed that different kinds of developers viewed different sets of questions; and, as all we had to use were traffic logs, we couldn’t really test any other assumptions anyway. Having moved forward regardless, we now know that we were correct, but at the time we were taking a gamble.
The Data
 A prerequisite for any useful analysis is data, and for our developer-kind predictions we needed labeled data. Seeing that Providence did not yet exist, this data had not been gathered. This is a chicken and egg problem that frequently popped up during the Providence project.
A prerequisite for any useful analysis is data, and for our developer-kind predictions we needed labeled data. Seeing that Providence did not yet exist, this data had not been gathered. This is a chicken and egg problem that frequently popped up during the Providence project.
Our solution was an activity we’ve taken to calling “labeling parties.” Every developer at Stack Exchange was asked to go and categorize several randomly chosen users based on their Stack Overflow Careers profile, and we used this to build a data set. For the developer-kinds problem, our labeling party hand classified 1,237 people.
The Classifier
In our experience, naïvely rubbing standard machine learning algorithms against our data rarely works. The same goes for developer-kinds. We attacked this problem in three different steps: structure, features, algorithms.
Looking over the different developer-kinds, it’s readily apparent that there’s an implicit hierarchy. Many kinds are some flavor of “web developer,” while others are “mobile developer,” and the remainder are fairly niche; we’ve taken to calling “web,” “mobile,” and “other” major developer-kinds. This observation led us to first classify the major developer-kind, and then proceed to the final labels.

Since we only really have question tag view data to use in the initial version of Providence, all of our features are naturally tag focused. The breakdowns of the groups of tags used in each classifier are:
- Major Developer-Kinds
- Web programming languages (java, c#, javascript, php, etc.)
- Mobile programming languages (java, objective-c, etc.)
- Non-web, non-mobile programming languages
- iDevices
- Web technologies (html, css, etc.)
- Mobile Developer-Kinds
- iDevice related (ios, objective-c, etc.)
- Android related (android, listview, etc.)
- Windows Phone related (window-phone, etc.)
- Other Developer-Kinds
- Each of the top 100 used tags on Stack Overflow
- Pairs of each of the top 100 used tags on Stack Overflow
- SQL related (sql, tsql, etc.)
- Database related (mysql, postgressql, etc.)
- Linux/Unix related (shell, bash, etc.)
- Math related (matlab, numpy, etc.)
For many features, rather than use the total tag views, we calculate an average and then use the deviation from that. With some features, we calculate this deviation for each developer-kind in the training set; for example, we calculate deviation from average web programming language tag views for each of the web, mobile, and other developer-kinds in the Major Developer Predictor.
Turning these features into final predictions requires an actual machine learning algorithm, but in my opinion, this is the least interesting bit of Providence. For these predictors we found that support vector machines, with a variety of kernels, produce acceptably accurate predictions; however, the choice of algorithm mattered little, various flavors of neural networks performed reasonably well, and the largest gains always came from introducing new features.
So how well did this classifier perform? Performance was determined with a split test of job listing ads with the control group being served with our existing algorithm which only considered geography, we’ll be covering our testing methodology in more depth in a future post. In the end we saw an improvement for 10-30% over the control algorithm, with the largest gains being seen in the Mobile Developer-Kinds and the smallest in the Web Developer-Kinds.
Next up: What technologies do you know?
Jil: Version 2.x, Dynamic Serialization, And More
Posted: 2014/09/15 Filed under: code Comments Off on Jil: Version 2.x, Dynamic Serialization, And MoreJil, a fast JSON serializer/deserializer for .NET, has hit 2.x! It’s gained a lot more perf work, some improved functionality, and dynamic serialization.
What’s Dynamic Serialization?
Jil has always supported static serialization via a generic type parameter. This would serialize exactly the provided type; things like inheritance, System.Object members, and the DLR were unsupported.
In .NET there are, broadly speaking, three “kinds” of dynamic behavior: polymorphism, reflection, and the dynamic language runtime. Jil now supports all three.
Polymorphism
Polymorphism comes up when you use subclasses. Consider the following.
class Foo
{
public string Fizz;
}
class Bar : Foo
{
public string Buzz;
}
Since Jil can’t know the Bar class exists when Serialize<Foo>(…) is first called, the Buzz member would never be serialized. SerializeDynamic(…), however, knows that the Foo class isn’t sealed and that the possibility of new members needs to be accounted for on every invocation. A similar situation exist with virtual members, which is also handled in SerializeDynamic.
Reflection
Reflection matters when the objects being serialized have normal .NET types (ints, strings, lists, user defined classes , and so on) at runtime but that type isn’t known at compile time. Consider the following.
object a = 123; object b = "hello world";
Calling Serialize(a) or Serialize(b) would infer a type of System.Object, since at compile time that’s the only information we have. Using SerializeDynamic, Jil knows to do a runtime lookup on the actual type of the passed in object.
Dynamic Runtime
The dynamic runtime backs the dynamic keyword in C#, but for Jil’s purposes it can be thought of as special casing types that implement IDynamicMetaObjectProvider.
While it’s rare to directly implement IDynamicMetaObjectProvider, code using ExpandoObject or DynamicObject isn’t unheard of. For example, Dapper uses ExpandoObject to implement its dynamic returns.
Speed Tricks
As usual, Jil focuses on speed although dynamic serialization is necessarily slower than static serialization.
Jil builds a custom serializer at each point in the type graph where the type could vary on subsequent calls. For example, if Jil sees a “MyAbstractClassBase” abstract class as a member it will do an extra lookup on each call to SerializeDynamic(…) to find out what the type really is for that invocation. If instead Jil sees a “string” or a “MyValueType” struct as a member, it knows that they cannot vary on subsequent calls and so will not do the extra lookup. This makes the first serialization involving a new type slower, but subsequent serializations are much faster.
The most common implementations of IDynamicMetaObjectProvider are special cased, ExpandoObject is treated as an IDictionary<string, object> and DynamicObject’s TryConvert(…) method is called directly. This avoids some very expensive trial casts that are sometimes necessary when serializing an implementer of IDynamicMetaObjectProvider.
Further Improvements
While dynamic serialization is the main new feature in 2.x, other improvements have been made.
A partial list of improvements:
- ISO8601 DateTimes now have Tick precision
- [JilDirective] alternatives to [DataMember] and [IgnoreDataMember]
- Static deserialization without a generic parameter
- Faster than hashing, automata based member and enum matching
Relative Speed Improvements
It’s been a while since I’ve posted Jil benchmarks, since most recent work has been on dynamic features that aren’t really comparable. However, lots of little improvements have added up to some non-trivial performance gains on the static end.
Overall serialization gains fall around 1% for the Stack Exchange API types, with the larger models and collections gaining a bit more.
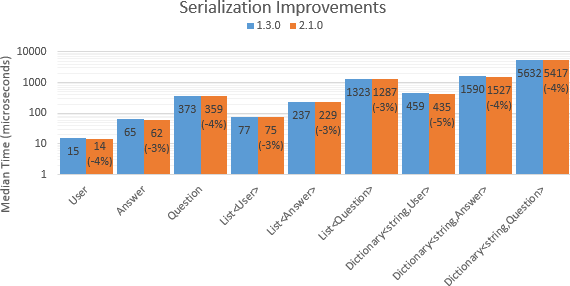
In the Stack Exchange API, deserialization of most models has seen speed increases north of 5% with largest models and collections seeing double-digit gains.

These numbers are available in a Google Doc were derived from Jil’s Benchmark project running on a machine with the following specs,:
- Operating System: Windows 8 Enterprise 64-bit
- Processor: Intel Core i7-3960X 3.30 GHz
- Ram: 64 GB
- DDR
- Quad Channel
- 800 MHz
The types used were taken from the Stack Exchange API to reflect a realistic workload, but as with all benchmarks take these numbers with a grain of salt.
I would also like to call out Paul Westcott’s (manofstick on Github) contributions to the Jil project, which have made some of these recent performance gains possible.
As always, you can
Browse the code on GitHub or Get Jil on NuGet
Jil: Dynamic Deserialization
Posted: 2014/04/14 Filed under: code 2 CommentsWith version 1.3.0 Jil now supports dynamic deserialization of JSON, with the appropriately named JSON.DeserializeDynamic(…) methods.
What Types Are Supported?
Jil’s dynamic deserializer parses the same set of types that its static deserializer does. Supported types are:
- Strings and Chars
- Booleans
- Integers
- Floating point numbers
- DateTimes
- Nullables
- Enumerations
- Guids, in the “D” format
- Arrays
- Objects
DateTime formats must be configured through an Options object, and includes four popular JSON date formats.
How Dynamic Is It?
Jil returns a dynamic object, introduced in C# 4, rather than some custom “JSON” class. Using the parsed object is done with natural feeling C# instead of method or indexer calls.
The following are supported operations on a Jil dynamic:
- Casts
- ie. (int)JSON.DeserializeDynamic(“123”)
- Member access
- ie. JSON.DeserializeDynamic(@”{“”A””:123}”).A
- Indexers
- ie. JSON.DeserializeDynamic(@”{“”A””:123}”)[“A”]
- or JSON.DeserializeDynamic(“[0, 1, 2]”)[0]
- Foreach loops
- ie. foreach(var keyValue in JSON.DeserializeDynamic(@”{“”A””:123}”)) { … }
- in this example, keyValue is a dynamic with Key and Value properties
- or foreach(var item in JSON.DeserializeDynamic(“[0, 1, 2]”)) { … }
- in this example, item is a dynamic and will have values 0, 1, and 2
- ie. foreach(var keyValue in JSON.DeserializeDynamic(@”{“”A””:123}”)) { … }
- Common unary operators (+, -, and !)
- Common binary operators (&&, ||, +, -, *, /, ==, !=, <, <=, >, and >=)
- .Length & .Count on arrays
- .ContainsKey(string) on objects
Jil also allows you to cast JSON arrays to IEnumerable<T>, JSON objects to IDictionary<string, T>, and either to plain IEnumerables.
Dynamic objects returned by Jil are immutable. Setting properties, setting through an indexer, .Add, +=, and so on are not supported and will throw exceptions at runtime.
Performance Tricks
As always, Jil works quite hard to be quite fast. While dynamic deserialization is necessarily somewhat slower than its static counterpart, it’s still quite fast.
Custom Number Parsers
.NET’s built in number parsers are much more general purpose than what Jil needs, so a custom parser that only does what is demanded by the JSON spec is used instead.
Custom Number Format
The JSON spec explicitly doesn’t specify the precision of numbers, and Jil exploits that to implement a non-IEEE794 floating point representation while parsing. Jil uses a less compact, but easier to parse, “Fast Number” of 169-bits for most purposes internally. Converting from this format to .NET’s built-in floating point values requires some extra work, but is still a net speed up for a small number of accesses. In addition, converting from integer “Fast Numbers” to .NET’s built-in integer types is quite fast.
Minimal Allocations
While dynamic dispatch implies a great many more allocations than with Jil’s static deserializer, the dynamic deserializer still strives to minimize them. You can see this in the methods for parsing strings, where a char[] is used if possible rather than allocating strings via a StringBuilder.
Benchmarks
Benchmarking dynamic code is tricky. Comparisons to other libraries may not be apples-to-apples if the same dynamic behavior hasn’t been implemented, or if parsing or conversion is delayed to different points.
Rather than put together a, quite possibly misleading, comparison to other JSON libraries. The following compares Jil’s dynamic deserializer to its static deserializer.

Comparison of Jil’s static and dynamic deserializers
The code for this benchmark can be found on Github.
While the dynamic deserializer is quite fast, it’s worth remember that dynamic dispatch is considerably slower than static dispatch and that some type conversions are deferred when deserializing dynamically. In practice this means that using the static deserializer is still noticeably faster than using the dynamic deserializer, but the dynamic deserializer is still usable for most purposes.
Grab the latest Jil on Nuget or Checkout the code on Github
After the inevitable bug fixes, I’ll probably be revisiting Jil’s existing SerializeDynamic() method to make it actually dynamic. Currently it only dynamically dispatches on the first type it sees, which isn’t nearly as useful.
Jil: Doing JSON Really, Really Quickly
Posted: 2014/02/03 Filed under: code 1 CommentAfter about three months of work, and some time in a production environment, the second half of Jil (a fast JSON library built on Sigil) is ready for release.
Jil now supports both serializing and deserializing JSON.
As with serialization, Jil deserialization supports very few configuration options and requires static typing. The interface is, accordingly, just a simple “JSON.Deserialize<T>(…)” which takes either a string or a TextReader.
The Numbers
Jil’s entire raison d’être is ridiculous optimizations in the name of speed, so let’s get right to the benchmarks.
Let’s start with the (recently updated) SimpleSpeedTester:
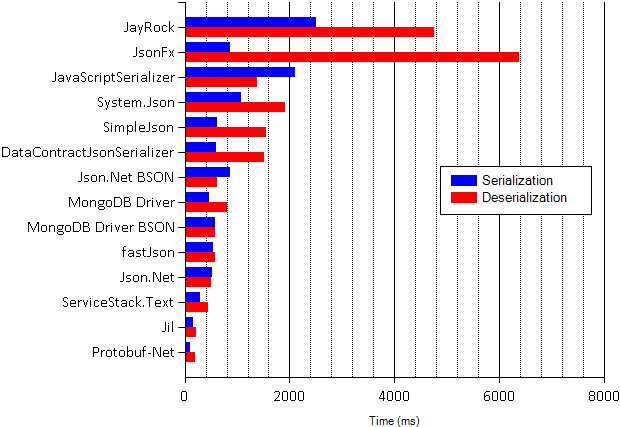
The numbers show Jil’s deserializers are about 50% faster than the next fastest JSON library. Protobuf-net is included as a baseline, it isn’t a JSON serializer (it does Protocol Buffers) but it’s the fastest .NET serializer (of anything) that I’m aware of.
The Tricks
Just like with serializing, Jil does runtime code generation using Sigil to produce tight, monolithic deserialization methods. That right there accounts for quite a lot of performance.
To speed up deserializing numbers, Jil has a large collection of methods tailored to each built-in number type. Deserializing bytes, for example, can omit sign checks and all but one overflow check. This specialization avoids unnecessary allocations, and sidesteps all the overhead in .NET imposed by support for culture-specific number formatting.
When deserializing JSON objects, Jil tries to avoid allocations when reading member names. It does this by checking to see if a hash function (Jil uses variants of the Fowler–Noll–Vo hash function) can be truncated into a jump table, ie. Jil calculates hash(memberName) % X for many Xs to see if a collision free option exists. If there’s an option that works, Jil uses it instead of actually storing member names which saves an allocation and the cost of a lookup in a Dictionary.
A fair amount of performance is gained by being very parsimonious with memory on the heap. Jil typically allocates a single character buffer, and may allocate a StringBuilder if certain conditions are met by the deserialized data. Additional string allocations will be made if Jil cannot use hash functions member name lookups.
Interested in Jil?
Grab It On Nuget or Checkout The Code
Next up is probably dynamic deserialization, though naturally I’d love to make the existing functionality even faster. Don’t hesitate to ping me with more performance tricks.
Jil: Serializing JSON Really, Really Quickly
Posted: 2013/11/13 Filed under: code 2 CommentsSeveral months ago I more or less finished up my “just for fun” coding side project Sigil (which I’ve written about a few times before), and started looking for something new to hack on. I settled on a JSON serializer for .NET that pulled out all the stops to be absolutely as fast as I could make it.
About three months later, I’m ready to start showing off…
Jil
a fast JSON serializer built on Sigil.
This is still a very early release (arbitrarily numbers 0.5.5, available on Nuget [but not in search results]), so there are a lot of caveats:
- Jil has very few configuration options
- Jil has very limited support for dynamic serialization
- Jil only serializes, no deserialization
- Jil only supports a subset of types
- Jil has seen very little production use
- At time of writing, Jil has been pulled into the Stack Exchange API for about a week without issue
Some Numbers
Benchmarks are most the exciting thing about Jil, so let’s get right to them. The following are from a fork of theburningmonk’s SimpleSpeedTester project.

In tabular form, the same data:

Raw numbers are available in a google document. There are also further benchmarks I created while making Jil on Github.
The take away from these benchmarks is that Jil is about twice as fast as the next fastest .NET JSON serializer. Protobuf-net is still faster (as you’d expect from an efficient binary protocol from Google and a library written by Marc Gravell) but Jil’s closer to it than to the next JSON serializer.
Some Tricks
I could write a whole series of how Jil shaves microseconds, and may yet do so. I’ll briefly go over some of the highlights right now, though.
The first one’s right there in the name, Jil is built on Sigil. That means a type’s serializer gets created in nice tight CIL, which becomes nice tight machine code, and no reflection at all occurs after the first call.
Second, Jil has a number of very specialized methods for converting data types into strings. Rather than relying on Object.ToString() or similar, Jil has a separate dedicated methods for shoving Int32s, UInt64s, Guids, and so on into character arrays. These specialized methods avoid extra allocations, sidestep all the culture-specific infrastructure .NET makes available, and let me do crazy things like divide exactly 14 times to print a DateTime.
As you’d expect of performance focused code in a garbage collected environment, the third thing Jil focuses on is trying not allocate anything, ever. In practice, Jil can keep allocations to a single small charactar array except when dealing with Guids and IDictionary<TKey, TValue>s. For Guids Jil must allocate an array for each since Guid.ToByteArray() doesn’t take a buffer, while serializing Dictionaries still allocates an enumerator.
If you’ve clicked through to Jil’s source by now, you might have noticed some MethodImpl attributes. That’s a part of the Jil’s fourth big trick, trading a fair amount of memory for more speed. Aggressively inlining code saves a few instructions spent branching, and even more time if instruction prefetching isn’t perfect in the face of method calls.
Last but not least, Jil avoids branches whenever possible; your CPU’s branch predictor can ruin your day. This means everything from using jump tables, to skipping negative checks on unsigned types, to only doing JSONP specific escaping when requested, and even baking configuration options into serializers to avoid the runtime checks. This does mean that Jil can create up to 64 different serializers for the same type, though in practice only a few different configurations are used within a single program.
Check Out The Code or Grab Jil From Nuget
I’m definitely interested in any crazy code that shaves more time off. Also faster ways to create a string (rather than write to a TextWriter), my experiment with capacity estimation works… but not for reliably enough speedups to flip it on by default.

